Heterogeneous Neural Networks¶
Neural networks are probably the most popular machine learning algorithms in recent years. FATE provides a federated Heterogeneous neural network implementation.
This federated heterogeneous neural network framework allows multiple parties to jointly conduct a learning process with partially overlapping user samples but different feature sets, which corresponds to a vertically partitioned virtual data set. An advantage of Hetero NN is that it provides the same level of accuracy as the non privacy-preserving approach while at the same time, reveal no information of each private data provider.
Basic FrameWork¶
The following figure shows the proposed Federated Heterogeneous Neural Network framework.
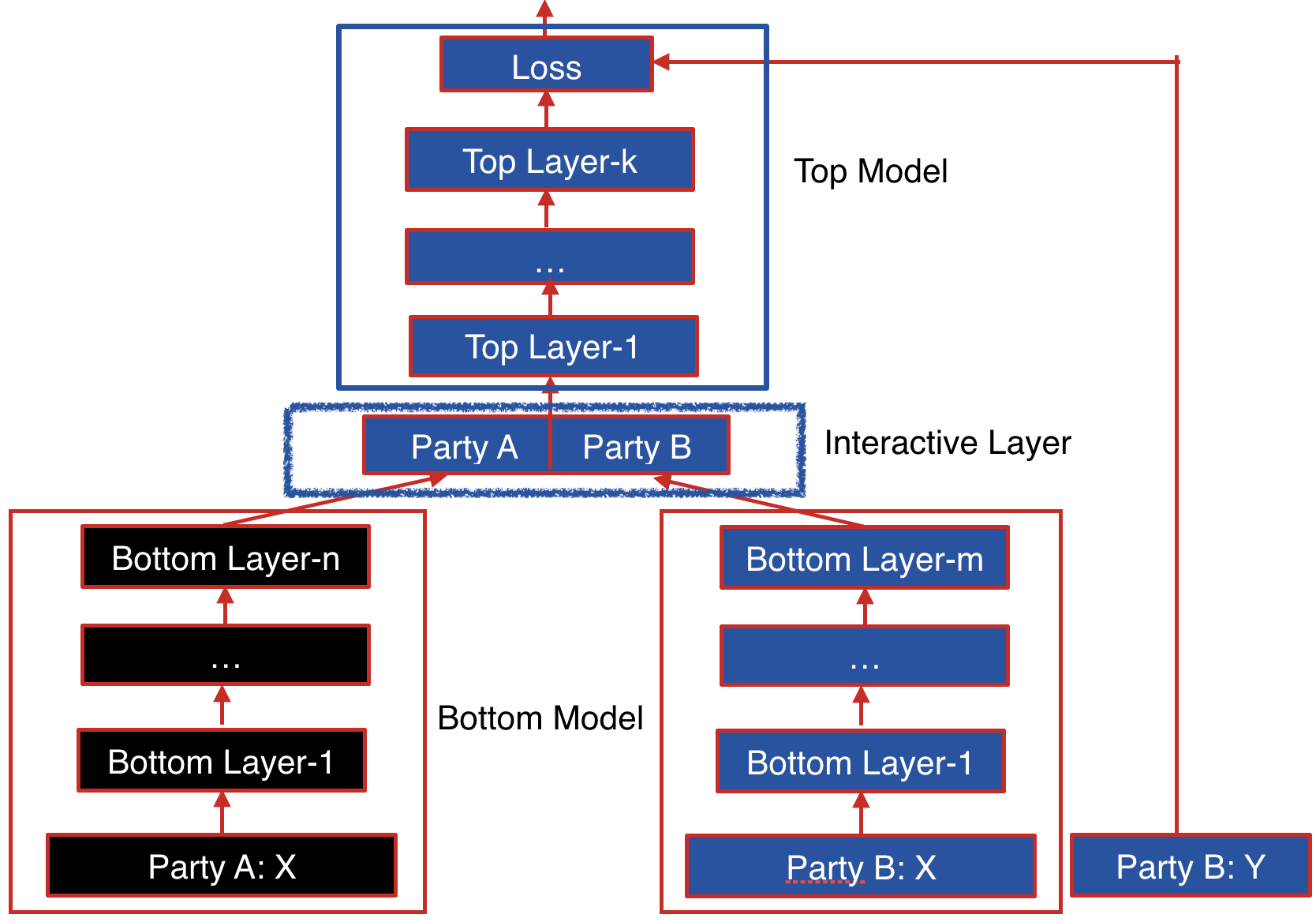
Party B: We define the party B as the data provider who holds both a data matrix and the class label. Since the class label information is indispensable for supervised learning, there must be an party with access to the label y. The party B naturally takes the responsibility as a dominating server in federated learning.
Party A: We define the data provider which has only a data matrix as party A. Party A plays the role of clients in the federated learning setting.
The data samples are aligned under an encryption scheme. By using the privacy-preserving protocol for inter-database intersections, the parties can find their common users or data samples without compromising the non-overlapping parts of the data sets.
Party B and party A each have their own bottom neural network model, which may be different. The parties jointly build the interactive layer, which is a fully connected layer. This layer's input is the concatenation of the two parties' bottom model output. In addition, only party B owns the model of interactive layer. Lastly, party B builds the top neural network model and feeds the output of interactive layer to it.
Forward Propagation of Federated Heterogeneous Neural Network¶
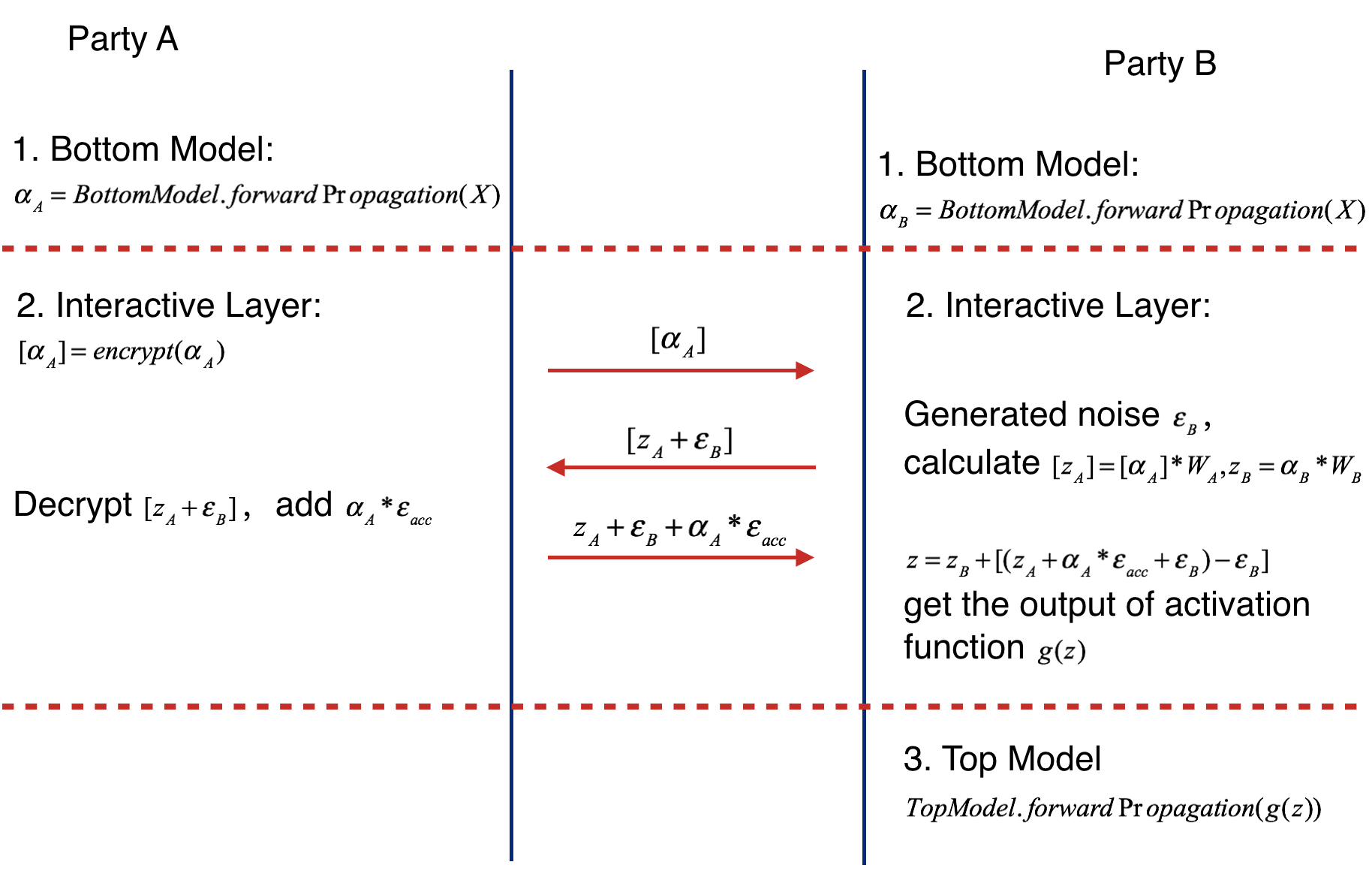
Forward Propagation Process consists of three parts.
- Part Ⅰ
Forward Propagation of Bottom Model.
- Party A feeds its input features X to its bottom model and gets the forward output of bottom model alpha_A
- Party B feeds its input features X to its bottom model and gets the forward output of bottom model alpha_B if active party has input features.
- Part ⅠⅠ
Forward Propagation of Interactive Layer.
- Party A uses additive homomorphic encryption to encrypt alpha_A(mark as ), and sends the encrypted result to party B.
- Party B receives the , multiplies it by interactive layer's party A model weight W_A, get . Party B also multiplies its interactive layer's weight W_B by its own bottom output, getting z_B. Party B generates noise epsilon_B, adds it to and sends addition result to party A.
- Party A calculates the product of accumulate noise epsilon_acc and bottom input alpha_A (epsilon_acc * alpha_A). Decrypting the received result , Party A adds the product to it and sends result to Active party.
- Party B subtracts the party A's sending value by epsilon_B( get z_A + epsilon_acc * alpha_A), and feeds z = z_A + epsilon_acc * alpha_A + z_B(if exists) to activation function.
- Part ⅠⅠⅠ
Forward Propagation of Top Model.
- Party B takes the output of activation function's output of interactive layer g(z) and runs the forward process of top model. The following figure shows the forward propagation of Federated Heterogeneous Neural Network framework.
Backward Propagation of Federated Heterogeneous Neural Network¶
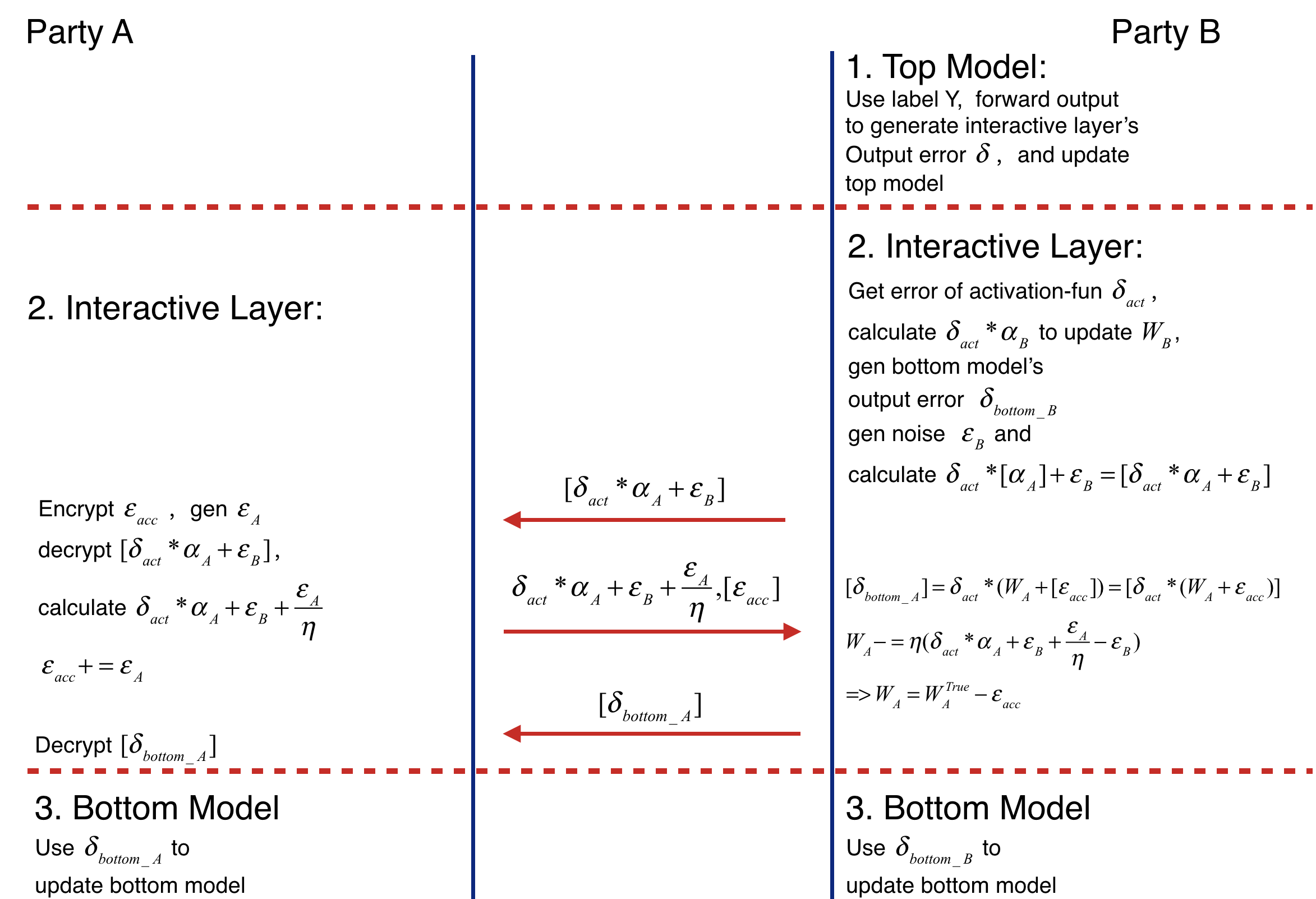
Backward Propagation Process also consists of three parts.
- Part I
Backward Propagation of Top Model.
- Party B calculates the error delta of interactive layer output, then updates top model.
- Part II
Backward Propagation of Interactive layer.
- Party B calculates the error delta_act of activation function's output by delta.
- Party B propagates delta_bottomB = delta_act * W_B to bottom model, then updates W_B(W_B -= eta * delta_act * alpha_B).
- Party B generates noise epsilon_B, calculates and sends it to party A.
- Party A encrypts epsilon_acc, sends to party B. Then party B decrypts the received value. Party A generates noise epsilon_A, adds epsilon_A / eta to decrypted result(delta_act * alpha_A + epsilon_B + epsilon_A / eta) and add epsilon_A to accumulate noise epsilon_acc(epsilon_acc += epsilon_A). Party A sends the addition result to party B. (delta_act * W_A + epsilon_B + epsilon_A / eta)
- Party B receives and delta_act * alpha_A + epsilon_B + epsilon_A / eta. Firstly it sends party A's bottom model output' error to party A. Secondly updates W_A -= eta * (delta_act * W_A + epsilon_B + epsilon_A / eta - epsilon_B) = eta * delta_act * W_A - epsilon_B = W_TRUE - epsilon_acc. Where W_TRUE represents the actually weights.
- Party A decrypts and passes delta_act * (W_A + acc) to its bottom model.
- Part III
Backward Propagation of Bottom Model.
- Party B and party A updates their bottom model separately. The following figure shows the backward propagation of Federated Heterogeneous Neural Network framework.
Param¶
hetero_nn_param
¶
Classes¶
DatasetParam(dataset_name=None, **kwargs)
¶
Bases: BaseParam
Source code in python/federatedml/param/hetero_nn_param.py
34 35 36 37 | |
Attributes¶
dataset_name = dataset_name
instance-attribute
¶param = kwargs
instance-attribute
¶Functions¶
check()
¶Source code in python/federatedml/param/hetero_nn_param.py
39 40 41 | |
to_dict()
¶Source code in python/federatedml/param/hetero_nn_param.py
43 44 45 | |
SelectorParam(method=None, beta=1, selective_size=consts.SELECTIVE_SIZE, min_prob=0, random_state=None)
¶
Bases: object
Parameters:
| Name | Type | Description | Default |
|---|---|---|---|
method |
back propagation select method, accept "relative" only, default: None |
None
|
|
selective_size |
deque size to use, store the most recent selective_size historical loss, default: 1024 |
consts.SELECTIVE_SIZE
|
|
beta |
sample whose selective probability >= power(np.random, beta) will be selected |
1
|
|
min_prob |
selective probability is max(min_prob, rank_rate) |
0
|
Source code in python/federatedml/param/hetero_nn_param.py
62 63 64 65 66 67 | |
Attributes¶
method = method
instance-attribute
¶selective_size = selective_size
instance-attribute
¶beta = beta
instance-attribute
¶min_prob = min_prob
instance-attribute
¶random_state = random_state
instance-attribute
¶Functions¶
check()
¶Source code in python/federatedml/param/hetero_nn_param.py
69 70 71 72 73 74 75 76 77 78 79 80 | |
CoAEConfuserParam(enable=False, epoch=50, lr=0.001, lambda1=1.0, lambda2=2.0, verbose=False)
¶
Bases: BaseParam
A label protect mechanism proposed in paper: "Batch Label Inference and Replacement Attacks in Black-Boxed Vertical Federated Learning" paper link: https://arxiv.org/abs/2112.05409 Convert true labels to fake soft labels by using an auto-encoder.
Args: enable: boolean run CoAE or not epoch: None or int auto-encoder training epochs lr: float auto-encoder learning rate lambda1: float parameter to control the difference between true labels and fake soft labels. Larger the parameter, autoencoder will give more attention to making true labels and fake soft label different. lambda2: float parameter to control entropy loss, see original paper for details verbose: boolean print loss log while training auto encoder
Source code in python/federatedml/param/hetero_nn_param.py
105 106 107 108 109 110 111 112 | |
Attributes¶
enable = enable
instance-attribute
¶epoch = epoch
instance-attribute
¶lr = lr
instance-attribute
¶lambda1 = lambda1
instance-attribute
¶lambda2 = lambda2
instance-attribute
¶verbose = verbose
instance-attribute
¶Functions¶
check()
¶Source code in python/federatedml/param/hetero_nn_param.py
114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 | |
HeteroNNParam(task_type='classification', bottom_nn_define=None, top_nn_define=None, interactive_layer_define=None, interactive_layer_lr=0.9, config_type='pytorch', optimizer='SGD', loss=None, epochs=100, batch_size=-1, early_stop='diff', tol=1e-05, seed=100, encrypt_param=EncryptParam(), encrypted_mode_calculator_param=EncryptedModeCalculatorParam(), predict_param=PredictParam(), cv_param=CrossValidationParam(), validation_freqs=None, early_stopping_rounds=None, metrics=None, use_first_metric_only=True, selector_param=SelectorParam(), floating_point_precision=23, callback_param=CallbackParam(), coae_param=CoAEConfuserParam(), dataset=DatasetParam())
¶
Bases: BaseParam
Parameters used for Hetero Neural Network.
Parameters:
| Name | Type | Description | Default |
|---|---|---|---|
task_type |
'classification'
|
||
bottom_nn_define |
None
|
||
interactive_layer_define |
None
|
||
interactive_layer_lr |
0.9
|
||
top_nn_define |
None
|
||
optimizer |
|
'SGD'
|
|
loss |
None
|
||
epochs |
100
|
||
batch_size |
int, batch size when updating model.
|
-1 means use all data in a batch. i.e. Not to use mini-batch strategy. defaults to -1. |
-1
|
early_stop |
str, accept 'diff' only in this version, default
|
Method used to judge converge or not. a) diff: Use difference of loss between two iterations to judge whether converge. |
'diff'
|
floating_point_precision |
e.g.: convert an x to round(x * 2**floating_point_precision) during Paillier operation, divide the result by 2**floating_point_precision in the end. |
23
|
|
callback_param |
CallbackParam()
|
Source code in python/federatedml/param/hetero_nn_param.py
164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 200 201 202 203 204 205 206 207 208 209 210 211 212 213 214 215 216 217 218 219 220 | |
Attributes¶
task_type = task_type
instance-attribute
¶bottom_nn_define = bottom_nn_define
instance-attribute
¶interactive_layer_define = interactive_layer_define
instance-attribute
¶interactive_layer_lr = interactive_layer_lr
instance-attribute
¶top_nn_define = top_nn_define
instance-attribute
¶batch_size = batch_size
instance-attribute
¶epochs = epochs
instance-attribute
¶early_stop = early_stop
instance-attribute
¶tol = tol
instance-attribute
¶optimizer = optimizer
instance-attribute
¶loss = loss
instance-attribute
¶validation_freqs = validation_freqs
instance-attribute
¶early_stopping_rounds = early_stopping_rounds
instance-attribute
¶metrics = metrics or []
instance-attribute
¶use_first_metric_only = use_first_metric_only
instance-attribute
¶encrypt_param = copy.deepcopy(encrypt_param)
instance-attribute
¶encrypted_model_calculator_param = encrypted_mode_calculator_param
instance-attribute
¶predict_param = copy.deepcopy(predict_param)
instance-attribute
¶cv_param = copy.deepcopy(cv_param)
instance-attribute
¶selector_param = selector_param
instance-attribute
¶floating_point_precision = floating_point_precision
instance-attribute
¶callback_param = copy.deepcopy(callback_param)
instance-attribute
¶coae_param = coae_param
instance-attribute
¶dataset = dataset
instance-attribute
¶seed = seed
instance-attribute
¶config_type = 'pytorch'
instance-attribute
¶Functions¶
check()
¶Source code in python/federatedml/param/hetero_nn_param.py
222 223 224 225 226 227 228 229 230 231 232 233 234 235 236 237 238 239 240 241 242 243 244 245 246 247 248 249 250 251 252 253 254 255 256 257 258 259 260 261 262 263 264 265 266 267 268 269 270 271 272 273 274 275 276 277 278 279 280 281 282 283 284 285 286 287 288 289 290 291 292 293 294 295 | |
Functions¶
Other features¶
- Allow party B's training without features.
- Support evaluate training and validate data during training process
- Support use early stopping strategy since FATE-v1.4.0
- Support selective backpropagation since FATE-v1.6.0
- Support low floating-point optimization since FATE-v1.6.0
- Support drop out strategy of interactive layer since FATE-v1.6.0
[1] Zhang Q, Wang C, Wu H, et al. GELU-Net: A Globally Encrypted, Locally Unencrypted Deep Neural Network for Privacy-Preserved Learning//IJCAI. 2018: 3933-3939.
[2] Zhang Y, Zhu H. Additively Homomorphical Encryption based Deep Neural Network for Asymmetrically Collaborative Machine Learning. arXiv preprint arXiv:2007.06849, 2020.