Federated Logistic Regression¶
Logistic Regression(LR) is a widely used statistic model for classification problems. FATE provided two modes of federated LR: Homogeneous LR (HomoLR) and Heterogeneous LR (HeteroLR and Hetero_SSHE_LR).
Below lists features of each LR models:
| Linear Model | Multiclass(OVR) | Arbiter-less Training | Weighted Training | Multi-Host | Cross Validation | Warm-Start/CheckPoint |
|---|---|---|---|---|---|---|
| Hetero LR | ✓ | ✗ | ✓ | ✓ | ✓ | ✓ |
| Hetero SSHELR | ✓ | ✓ | ✓ | ✗ | ✓ | ✓ |
| Homo LR | ✓ | ✗ | ✓ | ✓ | ✓ | ✓ |
We simplified the federation process into three parties. Party A represents Guest, party B represents Host while party C, which also known as "Arbiter", is a third party that holds a private key for each party and work as a coordinator. (Hetero_SSHE_LR have not "Arbiter" role)
Homogeneous LR¶
As the name suggested, in HomoLR, the feature spaces of guest and hosts are identical. An optional encryption mode for computing gradients is provided for host parties. By doing this, the plain model is not available for this host any more.
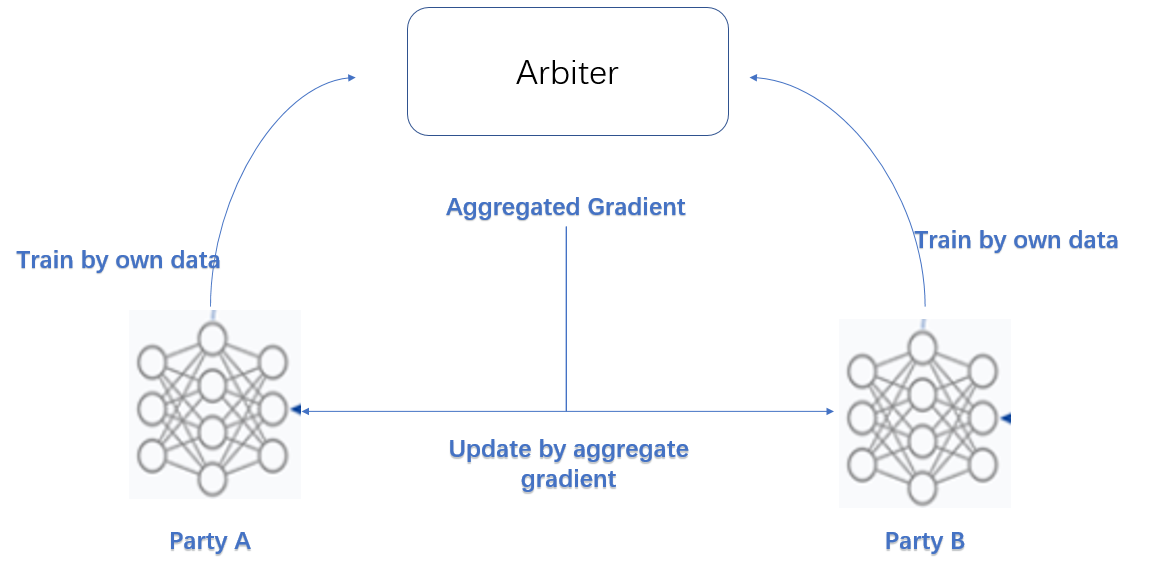
Models of Party A and Party B have the same structure. In each iteration, each party trains its model on its own data. After that, all parties upload their encrypted (or plain, depends on your configuration) gradients to arbiter. The arbiter aggregates these gradients to form a federated gradient that will then be distributed to all parties for updating their local models. Similar to traditional LR, the training process will stop when the federated model converges or the whole training process reaches a predefined max-iteration threshold. More details is available in this Practical Secure Aggregation for Privacy-Preserving Machine Learning.
Heterogeneous LR¶
The HeteroLR carries out the federated learning in a different way. As shown in Figure 2, A sample alignment process is conducted before training. This sample alignment process is to identify overlapping samples stored in databases of the two involved parties. The federated model is built based on those overlapping samples. The whole sample alignment process will not leak confidential information (e.g., sample ids) on the two parties since it is conducted in an encrypted way.
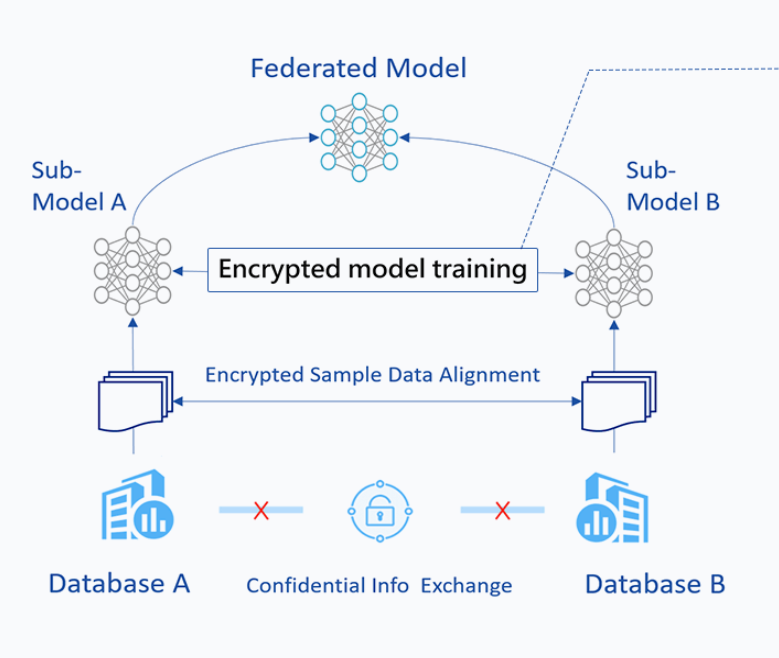
In the training process, party A and party B compute out the elements needed for final gradients. Arbiter aggregate them and compute out the gradient and then transfer back to each party. More details is available in this: Private federated learning on vertically partitioned data via entity resolution and additively homomorphic encryption.
Multi-host hetero-lr¶
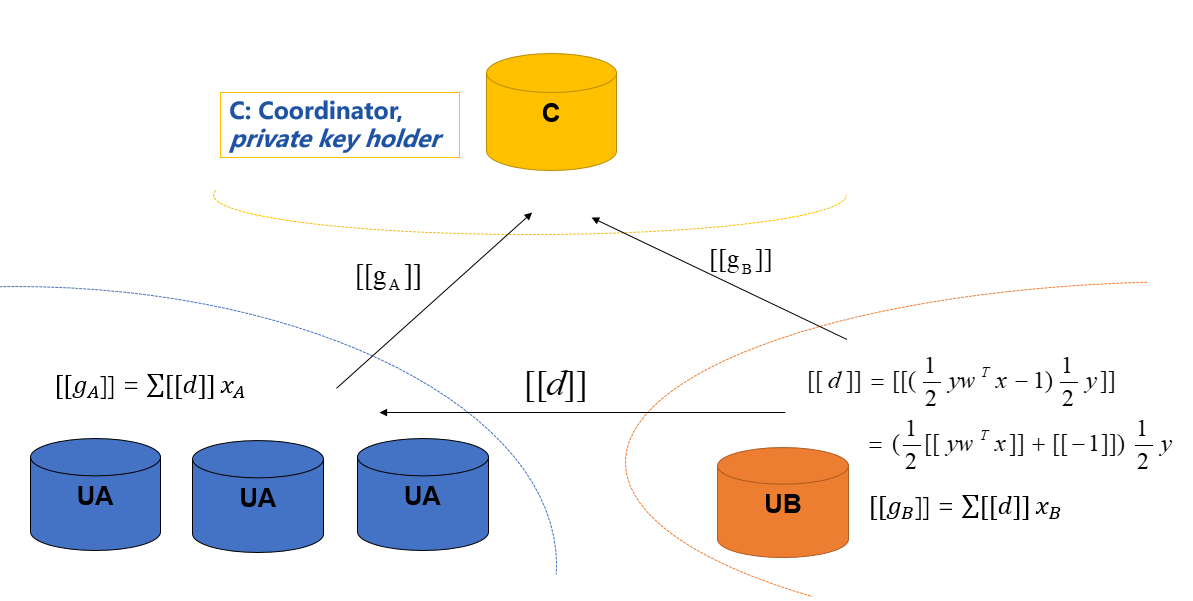
For multi-host scenario, the gradient computation still keep the same as single-host case. However, we use the second-norm of the difference of model weights between two consecutive iterations as the convergence criterion. Since the arbiter can obtain the completed model weight, the convergence decision is happening in Arbiter.
Heterogeneous SSHE Logistic Regression¶
FATE implements a heterogeneous logistic regression without arbiter role
called for hetero_sshe_lr. More details is available in this
following paper: When Homomorphic Encryption Marries Secret Sharing:
Secure Large-Scale Sparse Logistic Regression and Applications
in Risk Control.
We have also made some optimization so that the code may not exactly
same with this paper.
The training process could be described as the
following: forward and backward process.
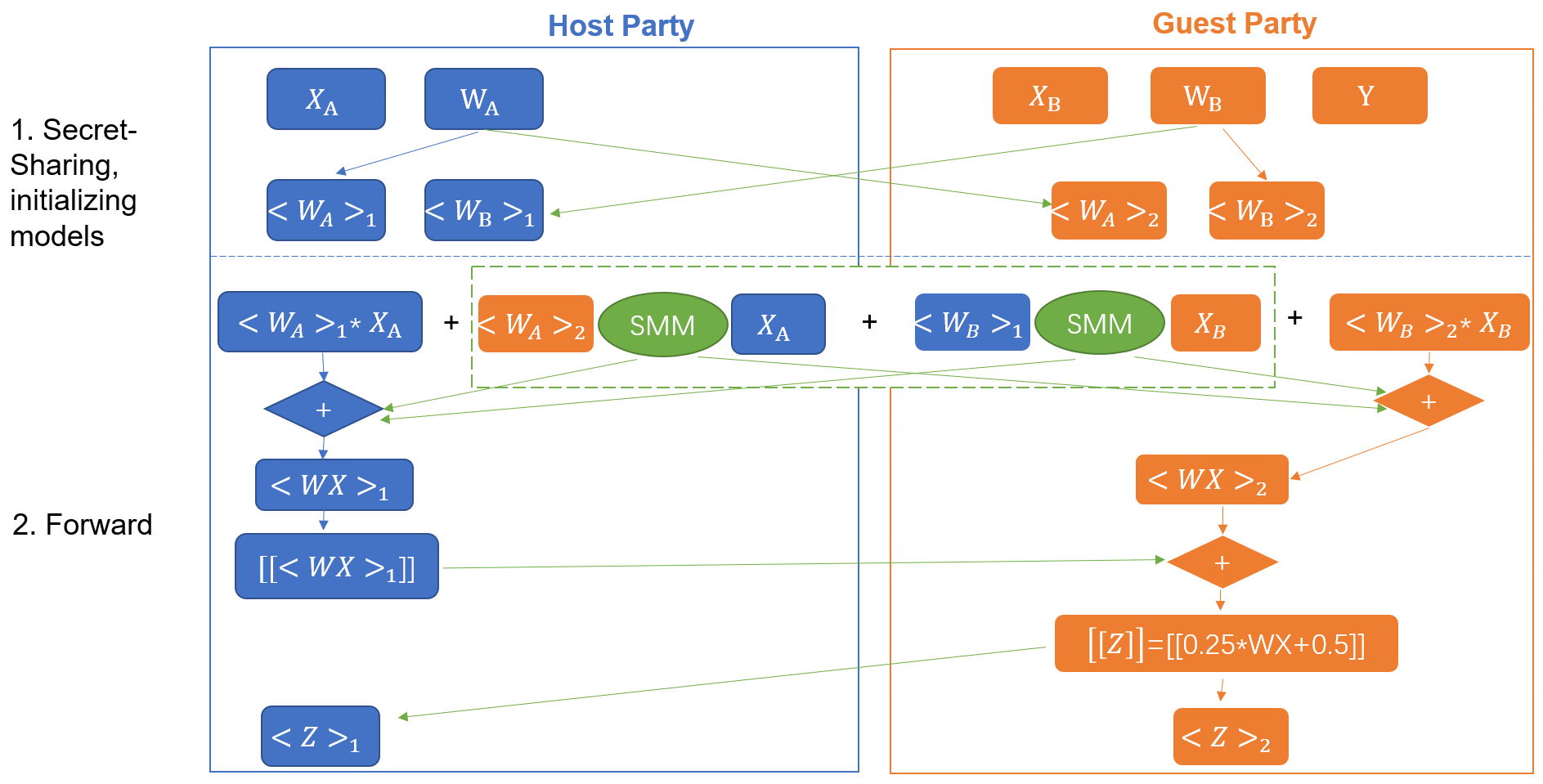
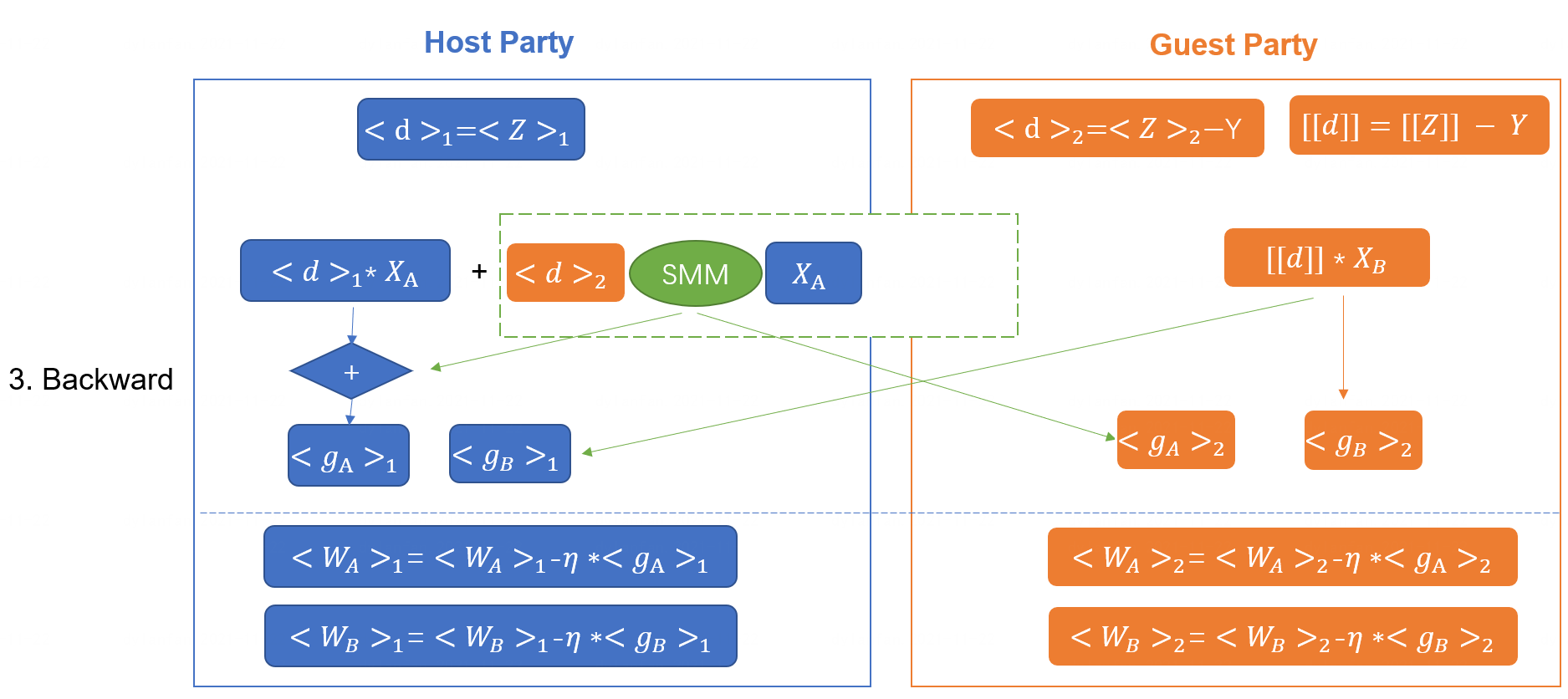
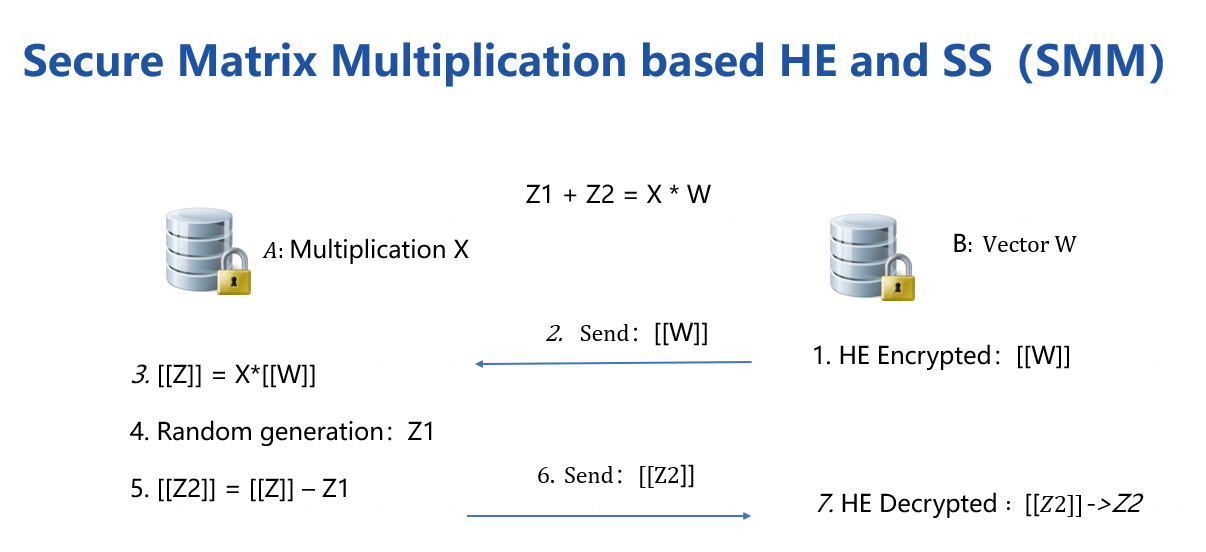
The training process is based secure matrix multiplication protocol(SMM),
which HE and Secret-Sharing hybrid protocol is included.
Param¶
logistic_regression_param
¶
Classes¶
LogisticParam(penalty='L2', tol=0.0001, alpha=1.0, optimizer='rmsprop', batch_size=-1, shuffle=True, batch_strategy='full', masked_rate=5, learning_rate=0.01, init_param=InitParam(), max_iter=100, early_stop='diff', encrypt_param=EncryptParam(), predict_param=PredictParam(), cv_param=CrossValidationParam(), decay=1, decay_sqrt=True, multi_class='ovr', validation_freqs=None, early_stopping_rounds=None, stepwise_param=StepwiseParam(), floating_point_precision=23, metrics=None, use_first_metric_only=False, callback_param=CallbackParam())
¶
Bases: LinearModelParam
Parameters used for Logistic Regression both for Homo mode or Hetero mode.
Parameters:
| Name | Type | Description | Default |
|---|---|---|---|
penalty |
Penalty method used in LR. Please note that, when using encrypted version in HomoLR, 'L1' is not supported. |
'L2'
|
|
tol |
float, default
|
The tolerance of convergence |
0.0001
|
alpha |
float, default
|
Regularization strength coefficient. |
1.0
|
optimizer |
Optimize method. |
'rmsprop'
|
|
batch_strategy |
str
|
Strategy to generate batch data. a) full: use full data to generate batch_data, batch_nums every iteration is ceil(data_size / batch_size) b) random: select data randomly from full data, batch_num will be 1 every iteration. |
'full'
|
batch_size |
int, default
|
Batch size when updating model. -1 means use all data in a batch. i.e. Not to use mini-batch strategy. |
-1
|
shuffle |
bool, default
|
Work only in hetero logistic regression, batch data will be shuffle in every iteration. |
True
|
masked_rate |
Use masked data to enhance security of hetero logistic regression |
5
|
|
learning_rate |
float, default
|
Learning rate |
0.01
|
max_iter |
int, default
|
The maximum iteration for training. |
100
|
early_stop |
Method used to judge converge or not. a) diff: Use difference of loss between two iterations to judge whether converge. b) weight_diff: Use difference between weights of two consecutive iterations c) abs: Use the absolute value of loss to judge whether converge. i.e. if loss < eps, it is converged. Please note that for hetero-lr multi-host situation, this parameter support "weight_diff" only. In homo-lr, weight_diff is not supported |
'diff'
|
|
decay |
Decay rate for learning rate. learning rate will follow the following decay schedule. lr = lr0/(1+decay*t) if decay_sqrt is False. If decay_sqrt is True, lr = lr0 / sqrt(1+decay*t) where t is the iter number. |
1
|
|
decay_sqrt |
lr = lr0/(1+decay*t) if decay_sqrt is False, otherwise, lr = lr0 / sqrt(1+decay*t) |
True
|
|
encrypt_param |
encrypt param |
EncryptParam()
|
|
predict_param |
predict param |
PredictParam()
|
|
callback_param |
callback param |
CallbackParam()
|
|
cv_param |
cv param |
CrossValidationParam()
|
|
multi_class |
If it is a multi_class task, indicate what strategy to use. Currently, support 'ovr' short for one_vs_rest only. |
'ovr'
|
|
validation_freqs |
validation frequency during training. |
None
|
|
early_stopping_rounds |
Will stop training if one metric doesn’t improve in last early_stopping_round rounds |
None
|
|
metrics |
Indicate when executing evaluation during train process, which metrics will be used. If set as empty, default metrics for specific task type will be used. As for binary classification, default metrics are ['auc', 'ks'] |
None
|
|
use_first_metric_only |
Indicate whether use the first metric only for early stopping judgement. |
False
|
|
floating_point_precision |
if not None, use floating_point_precision-bit to speed up calculation, e.g.: convert an x to round(x * 2**floating_point_precision) during Paillier operation, divide the result by 2**floating_point_precision in the end. |
23
|
Source code in python/federatedml/param/logistic_regression_param.py
103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 | |
Attributes¶
penalty = penalty
instance-attribute
¶tol = tol
instance-attribute
¶alpha = alpha
instance-attribute
¶optimizer = optimizer
instance-attribute
¶batch_size = batch_size
instance-attribute
¶learning_rate = learning_rate
instance-attribute
¶init_param = copy.deepcopy(init_param)
instance-attribute
¶max_iter = max_iter
instance-attribute
¶early_stop = early_stop
instance-attribute
¶encrypt_param = encrypt_param
instance-attribute
¶shuffle = shuffle
instance-attribute
¶batch_strategy = batch_strategy
instance-attribute
¶masked_rate = masked_rate
instance-attribute
¶predict_param = copy.deepcopy(predict_param)
instance-attribute
¶cv_param = copy.deepcopy(cv_param)
instance-attribute
¶decay = decay
instance-attribute
¶decay_sqrt = decay_sqrt
instance-attribute
¶multi_class = multi_class
instance-attribute
¶validation_freqs = validation_freqs
instance-attribute
¶stepwise_param = copy.deepcopy(stepwise_param)
instance-attribute
¶early_stopping_rounds = early_stopping_rounds
instance-attribute
¶metrics = metrics or []
instance-attribute
¶use_first_metric_only = use_first_metric_only
instance-attribute
¶floating_point_precision = floating_point_precision
instance-attribute
¶callback_param = copy.deepcopy(callback_param)
instance-attribute
¶Functions¶
check()
¶Source code in python/federatedml/param/logistic_regression_param.py
143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 | |
HomoLogisticParam(penalty='L2', tol=0.0001, alpha=1.0, optimizer='rmsprop', batch_size=-1, learning_rate=0.01, init_param=InitParam(), max_iter=100, early_stop='diff', predict_param=PredictParam(), cv_param=CrossValidationParam(), decay=1, decay_sqrt=True, aggregate_iters=1, multi_class='ovr', validation_freqs=None, metrics=['auc', 'ks'], callback_param=CallbackParam())
¶
Bases: LogisticParam
Parameters:
| Name | Type | Description | Default |
|---|---|---|---|
aggregate_iters |
int, default
|
Indicate how many iterations are aggregated once. |
1
|
Source code in python/federatedml/param/logistic_regression_param.py
171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 | |
Attributes¶
aggregate_iters = aggregate_iters
instance-attribute
¶Functions¶
check()
¶Source code in python/federatedml/param/logistic_regression_param.py
194 195 196 197 198 199 200 201 202 | |
HeteroLogisticParam(penalty='L2', tol=0.0001, alpha=1.0, optimizer='rmsprop', batch_size=-1, shuffle=True, batch_strategy='full', masked_rate=5, learning_rate=0.01, init_param=InitParam(), max_iter=100, early_stop='diff', encrypted_mode_calculator_param=EncryptedModeCalculatorParam(), predict_param=PredictParam(), cv_param=CrossValidationParam(), decay=1, decay_sqrt=True, sqn_param=StochasticQuasiNewtonParam(), multi_class='ovr', validation_freqs=None, early_stopping_rounds=None, metrics=['auc', 'ks'], floating_point_precision=23, encrypt_param=EncryptParam(), use_first_metric_only=False, stepwise_param=StepwiseParam(), callback_param=CallbackParam())
¶
Bases: LogisticParam
Source code in python/federatedml/param/logistic_regression_param.py
206 207 208 209 210 211 212 213 214 215 216 217 218 219 220 221 222 223 224 225 226 227 228 229 230 231 232 233 234 235 236 237 | |
Attributes¶
encrypted_mode_calculator_param = copy.deepcopy(encrypted_mode_calculator_param)
instance-attribute
¶sqn_param = copy.deepcopy(sqn_param)
instance-attribute
¶Functions¶
check()
¶Source code in python/federatedml/param/logistic_regression_param.py
239 240 241 242 243 | |
Functions¶
Features¶
- Both Homo-LR and Hetero-LR
L1 & L2 regularization
Mini-batch mechanism
Weighted training
Six optimization method:
sgd
gradient descent with arbitrary batch sizermsprop
RMSPropadam
Adamadagrad
AdaGradnesterov_momentum_sgd
Nesterov MomentumThree converge criteria:
diff
Use difference of loss between two iterations, not available for multi-host training;abs
use the absolute value of loss;weight_diff
use difference of model weightsSupport multi-host modeling task.
Support validation for every arbitrary iterations
Learning rate decay mechanism
- Homo-LR extra features
Two Encryption mode
"Paillier" mode
Host will not get clear text model. When using encryption mode, "sgd" optimizer is supported only.Non-encryption mode
Everything is in clear text.Secure aggregation mechanism used when more aggregating models
Support aggregate for every arbitrary iterations.
Support FedProx mechanism. More details is available in this Federated Optimization in Heterogeneous Networks.
-
Hetero-LR extra features
-
Support different encrypt-mode to balance speed and security
- Support OneVeRest
- When modeling a multi-host task, "weight_diff" converge criteria
is supported only. - Support sparse format data
- Support early-stopping mechanism
- Support setting arbitrary metrics for validation during training
- Support stepwise. For details on stepwise mode, please refer stepwise.
-
Support batch shuffle and batch masked strategy.
-
Hetero-SSHE-LR extra features
- Support different encrypt-mode to balance speed and security
- Support OneVeRest
- Support early-stopping mechanism
- Support setting arbitrary metrics for validation during training
- Support model encryption with host model