Homogeneous Neural Networks¶
Neural networks are probably the most popular machine learning algorithms in recent years. FATE provides a federated homogeneous neural network implementation. We simplified the federation process into three parties. Party A represents Guest,which acts as a task trigger. Party B represents Host, which is almost the same with guest except that Host does not initiate task. Party C serves as a coordinator to aggregate models from guest/hosts and broadcast aggregated model.
Basic Process¶
As its name suggested, in Homogeneous Neural Networks, the feature spaces of guest and hosts are identical. An optional encryption mode for model is provided. By doing this, no party can get the private model of other parties.
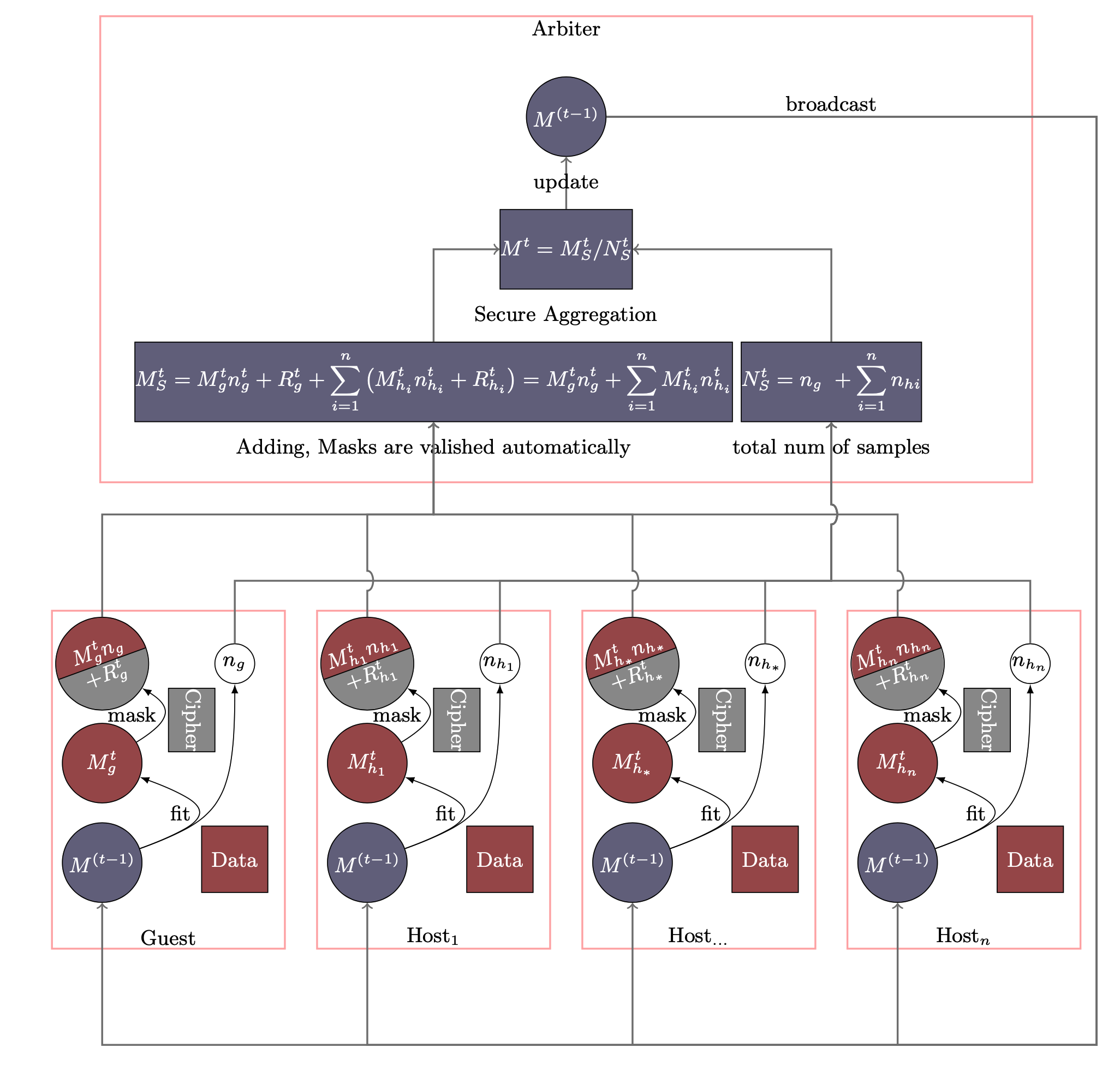
The Homo NN process is shown in Figure 1. Models of Party A and Party B have the same neural networks structure. In each iteration, each party trains its model on its own data. After that, all parties upload their encrypted (with random mask) model parameters to arbiter. The arbiter aggregates these parameters to form a federated model parameter, which will then be distributed to all parties for updating their local models. Similar to traditional neural network, the training process will stop when the federated model converges or the whole training process reaches a predefined max-iteration threshold.
Please note that random numbers are carefully generated so that the random numbers of all parties add up an zero matrix and thus disappear automatically. For more detailed explanations, please refer to Secure Analytics: Federated Learning and Secure Aggregation. Since there is no model transferred in plaintext, except for the owner of the model, no other party can obtain the real information of the model.
Param¶
homo_nn_param
¶
Classes¶
HomoNNParam(api_version=0, secure_aggregate=True, aggregate_every_n_epoch=1, config_type='nn', nn_define=None, optimizer='SGD', loss=None, metrics=None, max_iter=100, batch_size=-1, early_stop='diff', encode_label=False, predict_param=PredictParam(), cv_param=CrossValidationParam(), callback_param=CallbackParam())
¶
Bases: BaseParam
Parameters used for Homo Neural Network.
Parameters:
| Name | Type | Description | Default |
|---|---|---|---|
secure_aggregate |
bool
|
enable secure aggregation or not, defaults to True. |
True
|
aggregate_every_n_epoch |
int
|
aggregate model every n epoch, defaults to 1. |
1
|
config_type |
str
|
config type |
"nn"
|
nn_define |
dict
|
a dict represents the structure of neural network. |
None
|
optimizer |
str or dict
|
optimizer method, accept following types: 1. a string, one of "Adadelta", "Adagrad", "Adam", "Adamax", "Nadam", "RMSprop", "SGD" 2. a dict, with a required key-value pair keyed by "optimizer", with optional key-value pairs such as learning rate. defaults to "SGD" |
'SGD'
|
loss |
str
|
loss |
None
|
metrics |
typing.Union[str, list]
|
metrics |
None
|
max_iter |
int
|
the maximum iteration for aggregation in training. |
100
|
batch_size |
int
|
batch size when updating model. -1 means use all data in a batch. i.e. Not to use mini-batch strategy. defaults to -1. |
-1
|
early_stop |
typing.Union[str, dict, SimpleNamespace]
|
Method used to judge converge or not. a) diff: Use difference of loss between two iterations to judge whether converge. b) weight_diff: Use difference between weights of two consecutive iterations c) abs: Use the absolute value of loss to judge whether converge. i.e. if loss < eps, it is converged. |
'diff'
|
encode_label |
bool
|
encode label to one_hot. |
False
|
Source code in federatedml/param/homo_nn_param.py
69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 | |
Attributes¶
api_version = api_version
instance-attribute
¶secure_aggregate = secure_aggregate
instance-attribute
¶aggregate_every_n_epoch = aggregate_every_n_epoch
instance-attribute
¶config_type = config_type
instance-attribute
¶nn_define = nn_define or []
instance-attribute
¶encode_label = encode_label
instance-attribute
¶batch_size = batch_size
instance-attribute
¶max_iter = max_iter
instance-attribute
¶early_stop = early_stop
instance-attribute
¶metrics = metrics
instance-attribute
¶optimizer = optimizer
instance-attribute
¶loss = loss
instance-attribute
¶predict_param = copy.deepcopy(predict_param)
instance-attribute
¶cv_param = copy.deepcopy(cv_param)
instance-attribute
¶callback_param = copy.deepcopy(callback_param)
instance-attribute
¶Functions¶
check()
¶Source code in federatedml/param/homo_nn_param.py
109 110 111 112 113 114 115 | |
generate_pb()
¶Source code in federatedml/param/homo_nn_param.py
117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 | |
restore_from_pb(pb, is_warm_start_mode=False)
¶Source code in federatedml/param/homo_nn_param.py
149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 | |
Features¶
tensorflow backend¶
supported layers¶
{
"layer": "Dense",
"units": ,
"activation": null,
"use_bias": true,
"kernel_initializer": "glorot_uniform",
"bias_initializer": "zeros",
"kernel_regularizer": null,
"bias_regularizer": null,
"activity_regularizer": null,
"kernel_constraint": null,
"bias_constraint": null
}
{
"rate": ,
"noise_shape": null,
"seed": null
}
other layers listed in tf.keras.layers will be supported in near feature.
supported optimizer¶
all optimizer listed in tf.keras.optimizers supported
{
"optimizer": "Adadelta",
"learning_rate": 0.001,
"rho": 0.95,
"epsilon": 1e-07
}
{
"optimizer": "Adagrad",
"learning_rate": 0.001,
"initial_accumulator_value": 0.1,
"epsilon": 1e-07
}
{
"optimizer": "Adam",
"learning_rate": 0.001,
"beta_1": 0.9,
"beta_2": 0.999,
"amsgrad": false,
"epsilon": 1e-07
}
{
"optimizer": "Ftrl",
"learning_rate": 0.001,
"learning_rate_power": -0.5,
"initial_accumulator_value": 0.1,
"l1_regularization_strength": 0.0,
"l2_regularization_strength": 0.0,
"l2_shrinkage_regularization_strength": 0.0
}
{
"optimizer": "Nadam",
"learning_rate": 0.001,
"beta_1": 0.9,
"beta_2": 0.999,
"epsilon": 1e-07
}
{
"optimizer": "RMSprop",
"learning_rate": 0.001,
"pho": 0.9,
"momentum": 0.0,
"epsilon": 1e-07,
"centered": false
}
{
"optimizer": "SGD",
"learning_rate": 0.001,
"momentum": 0.0,
"nesterov": false
}
supported losses¶
all losses listed in tf.keras.losses supported
- binary_crossentropy
- categorical_crossentropy
- categorical_hinge
- cosine_similarity
- hinge
- kullback_leibler_divergence
- logcosh
- mean_absolute_error
- mean_absolute_percentage_error
- mean_squared_error
- mean_squared_logarithmic_error
- poisson
- sparse_categorical_crossentropy
- squared_hinge
support multi-host¶
In fact, for model security reasons, at least two host parties are required.
pytorch backend¶
There are some difference in nn configuration build by pytorch compared to tf or keras.
-
config_type
pytorch, if use pytorch to build your model -
nn_define
Each layer is represented as an object in json.
supported layers¶
Linear
{
"layer": "Linear",
"name": #string,
"type": "normal",
"config": [input_num,output_num]
}
other normal layers
-
BatchNorm2d
-
dropout
supportd activate¶
Rulu
{ "layer": "Relu", "type": "activate", "name": #string }
-
other activate layers
-
Selu
- LeakyReLU
- Tanh
- Sigmoid
- Relu
- Tanh
supported optimizer¶
A json object is needed
Adam
"optimizer": {
"optimizer": "Adam",
"learning_rate": 0.05
}
optimizer include "Adam","SGD","RMSprop","Adagrad"
supported loss¶
A string is needed, supported losses include:
- "CrossEntropyLoss"
- "MSELoss"
- "BCELoss"
- "BCEWithLogitsLoss"
- "NLLLoss"
- "L1Loss"
- "SmoothL1Loss"
- "HingeEmbeddingLoss"
supported metrics¶
A string is needed, supported metrics include:
- auccuray
- precision
- recall
- auc
- f1
- fbeta
Use¶
Since all parties training Homogeneous Neural Networks have the same network structure, a common practice is to configure parameters under algorithm_parameters, which is shared across all parties. The basic structure is:
{
"config_type": "nn",
"nn_define": [layer1, layer2, ...]
"batch_size": -1,
"optimizer": optimizer,
"early_stop": {
"early_stop": early_stop_type,
"eps": 1e-4
},
"loss": loss,
"metrics": [metrics1, metrics2, ...],
"max_iter": 10
}
-
nn_define
Each layer is represented as an object in json. Please refer to supported layers in Features part. -
optimizer
A json object is needed, please refer to supported optimizers in Features part. -
loss
A string is needed, please refer to supported losses in Features part. -
others
-
batch_size: a positive integer or -1 for full batch
- max_iter: max aggregation number, a positive integer
- early_stop: diff or abs
- metrics: a string name, refer to metrics doc, such as Accuracy, AUC ...
Examples¶
Example
## Homo Neural Networddk Pipeline Example Usage Guide.
#### Example Tasks
This section introduces the Pipeline scripts for different types of tasks.
1. Single layer Task:
script: pipeline_homo_nn_single_layer.py
2. Multi layer Task:
script: pipeline_homo_nn_multi_layer.py
3. Multi label and multi host Task:
script: pipeline_homo_nn_multi_label.py
Users can run a pipeline job directly:
python ${pipeline_script}
pipeline_homo_nn_multi_label.py
import argparse
from pipeline.backend.pipeline import PipeLine
from pipeline.component.data_transform import DataTransform
from pipeline.component.homo_nn import HomoNN
from pipeline.component.reader import Reader
from pipeline.interface import Data
from pipeline.utils.tools import load_job_config
from tensorflow.keras import optimizers
from tensorflow.keras.layers import Dense
def main(config="../../config.yaml", namespace=""):
homo_nn_0 = HomoNN(
name="homo_nn_0",
encode_label=True,
max_iter=15,
batch_size=-1,
early_stop={"early_stop": "diff", "eps": 0.0001},
)
homo_nn_0.add(Dense(units=5, input_shape=(18,), activation="relu"))
homo_nn_0.add(Dense(units=4, activation="sigmoid"))
homo_nn_0.compile(
optimizer=optimizers.Adam(learning_rate=0.05),
metrics=["accuracy"],
loss="categorical_crossentropy",
)
run_homo_nn_pipeline(config, namespace, dataset.vehicle, homo_nn_0, 2)
def run_homo_nn_pipeline(config, namespace, data: dict, nn_component, num_host):
if isinstance(config, str):
config = load_job_config(config)
guest_train_data = data["guest"]
host_train_data = data["host"][:num_host]
for d in [guest_train_data, *host_train_data]:
d["namespace"] = f"{d['namespace']}{namespace}"
hosts = config.parties.host[:num_host]
pipeline = (
PipeLine()
.set_initiator(role="guest", party_id=config.parties.guest[0])
.set_roles(
guest=config.parties.guest[0], host=hosts, arbiter=config.parties.arbiter
)
)
reader_0 = Reader(name="reader_0")
reader_0.get_party_instance(
role="guest", party_id=config.parties.guest[0]
).component_param(table=guest_train_data)
for i in range(num_host):
reader_0.get_party_instance(role="host", party_id=hosts[i]).component_param(
table=host_train_data[i]
)
data_transform_0 = DataTransform(name="data_transform_0", with_label=True)
data_transform_0.get_party_instance(
role="guest", party_id=config.parties.guest[0]
).component_param(with_label=True, output_format="dense")
data_transform_0.get_party_instance(role="host", party_id=hosts).component_param(
with_label=True
)
pipeline.add_component(reader_0)
pipeline.add_component(data_transform_0, data=Data(data=reader_0.output.data))
pipeline.add_component(
nn_component, data=Data(train_data=data_transform_0.output.data)
)
pipeline.compile()
pipeline.fit()
print(pipeline.get_component("homo_nn_0").get_summary())
pipeline.deploy_component([data_transform_0, nn_component])
# predict
predict_pipeline = PipeLine()
predict_pipeline.add_component(reader_0)
predict_pipeline.add_component(
pipeline,
data=Data(
predict_input={pipeline.data_transform_0.input.data: reader_0.output.data}
),
)
# run predict model
predict_pipeline.predict()
# noinspection PyPep8Naming
class dataset_meta(type):
@property
def breast(cls):
return {
"guest": {"name": "breast_homo_guest", "namespace": "experiment"},
"host": [
{"name": "breast_homo_host", "namespace": "experiment"},
{"name": "breast_homo_host", "namespace": "experiment"},
],
}
@property
def vehicle(cls):
return {
"guest": {"name": "vehicle_scale_homo_guest", "namespace": "experiment", },
"host": [
{"name": "vehicle_scale_homo_host", "namespace": "experiment"},
{"name": "vehicle_scale_homo_host", "namespace": "experiment"},
],
}
class dataset(metaclass=dataset_meta):
...
if __name__ == "__main__":
parser = argparse.ArgumentParser("PIPELINE DEMO")
parser.add_argument("-config", type=str, help="config file")
args = parser.parse_args()
if args.config is not None:
main(args.config)
else:
main()
homo_nn_testsuite.json
{
"data": [
{
"file": "examples/data/breast_homo_guest.csv",
"head": 1,
"partition": 16,
"table_name": "breast_homo_guest",
"namespace": "experiment",
"role": "guest_0"
},
{
"file": "examples/data/breast_homo_host.csv",
"head": 1,
"partition": 16,
"table_name": "breast_homo_host",
"namespace": "experiment",
"role": "host_0"
},
{
"file": "examples/data/vehicle_scale_homo_guest.csv",
"head": 1,
"partition": 16,
"table_name": "vehicle_scale_homo_guest",
"namespace": "experiment",
"role": "guest_0"
},
{
"file": "examples/data/vehicle_scale_homo_host.csv",
"head": 1,
"partition": 16,
"table_name": "vehicle_scale_homo_host",
"namespace": "experiment",
"role": "host_0"
},
{
"file": "examples/data/vehicle_scale_homo_host.csv",
"head": 1,
"partition": 16,
"table_name": "vehicle_scale_homo_host",
"namespace": "experiment",
"role": "host_1"
}
],
"pipeline_tasks": {
"single_layer": {
"script": "./pipeline_homo_nn_single_layer.py"
},
"multi_layer": {
"script": "./pipeline_homo_nn_multi_layer.py"
},
"multi_label": {
"script": "./pipeline_homo_nn_multi_label.py"
}
}
}
pipeline_homo_nn_multi_layer.py
import argparse
from pipeline.backend.pipeline import PipeLine
from pipeline.component.data_transform import DataTransform
from pipeline.component.homo_nn import HomoNN
from pipeline.component.reader import Reader
from pipeline.interface import Data
from pipeline.utils.tools import load_job_config
from tensorflow.keras import optimizers
from tensorflow.keras.layers import Dense
def main(config="../../config.yaml", namespace=""):
homo_nn_0 = HomoNN(
name="homo_nn_0",
max_iter=10,
batch_size=-1,
early_stop={"early_stop": "diff", "eps": 0.0001},
)
homo_nn_0.add(Dense(units=6, input_shape=(10,), activation="relu"))
homo_nn_0.add(Dense(units=1, activation="sigmoid"))
homo_nn_0.compile(
optimizer=optimizers.Adam(learning_rate=0.05),
metrics=["Hinge", "accuracy", "AUC"],
loss="binary_crossentropy",
)
run_homo_nn_pipeline(config, namespace, dataset.breast, homo_nn_0, 1)
def run_homo_nn_pipeline(config, namespace, data: dict, nn_component, num_host):
if isinstance(config, str):
config = load_job_config(config)
guest_train_data = data["guest"]
host_train_data = data["host"][:num_host]
for d in [guest_train_data, *host_train_data]:
d["namespace"] = f"{d['namespace']}{namespace}"
hosts = config.parties.host[:num_host]
pipeline = (
PipeLine()
.set_initiator(role="guest", party_id=config.parties.guest[0])
.set_roles(
guest=config.parties.guest[0], host=hosts, arbiter=config.parties.arbiter
)
)
reader_0 = Reader(name="reader_0")
reader_0.get_party_instance(
role="guest", party_id=config.parties.guest[0]
).component_param(table=guest_train_data)
for i in range(num_host):
reader_0.get_party_instance(role="host", party_id=hosts[i]).component_param(
table=host_train_data[i]
)
data_transform_0 = DataTransform(name="data_transform_0", with_label=True)
data_transform_0.get_party_instance(
role="guest", party_id=config.parties.guest[0]
).component_param(with_label=True, output_format="dense")
data_transform_0.get_party_instance(role="host", party_id=hosts).component_param(
with_label=True
)
pipeline.add_component(reader_0)
pipeline.add_component(data_transform_0, data=Data(data=reader_0.output.data))
pipeline.add_component(
nn_component, data=Data(train_data=data_transform_0.output.data)
)
pipeline.compile()
pipeline.fit()
print(pipeline.get_component("homo_nn_0").get_summary())
pipeline.deploy_component([data_transform_0, nn_component])
# predict
predict_pipeline = PipeLine()
predict_pipeline.add_component(reader_0)
predict_pipeline.add_component(
pipeline,
data=Data(
predict_input={pipeline.data_transform_0.input.data: reader_0.output.data}
),
)
# run predict model
predict_pipeline.predict()
# noinspection PyPep8Naming
class dataset_meta(type):
@property
def breast(cls):
return {
"guest": {"name": "breast_homo_guest", "namespace": "experiment"},
"host": [
{"name": "breast_homo_host", "namespace": "experiment"},
{"name": "breast_homo_host", "namespace": "experiment"},
],
}
@property
def vehicle(cls):
return {
"guest": {"name": "vehicle_scale_homo_guest", "namespace": "experiment", },
"host": [
{"name": "vehicle_scale_homo_host", "namespace": "experiment"},
{"name": "vehicle_scale_homo_host", "namespace": "experiment"},
],
}
class dataset(metaclass=dataset_meta):
...
if __name__ == "__main__":
parser = argparse.ArgumentParser("PIPELINE DEMO")
parser.add_argument("-config", type=str, help="config file")
args = parser.parse_args()
if args.config is not None:
main(args.config)
else:
main()
pipeline_homo_nn_single_layer.py
import argparse
from pipeline.backend.pipeline import PipeLine
from pipeline.component.data_transform import DataTransform
from pipeline.component.homo_nn import HomoNN
from pipeline.component.reader import Reader
from pipeline.interface import Data
from pipeline.utils.tools import load_job_config
from tensorflow.keras import optimizers
from tensorflow.keras.layers import Dense
def main(config="../../config.yaml", namespace=""):
homo_nn_0 = HomoNN(
name="homo_nn_0",
max_iter=10,
batch_size=-1,
early_stop={"early_stop": "diff", "eps": 0.0001},
)
homo_nn_0.add(Dense(units=1, input_shape=(10,), activation="sigmoid"))
homo_nn_0.compile(
optimizer=optimizers.Adam(learning_rate=0.05),
metrics=["accuracy", "AUC"],
loss="binary_crossentropy",
)
run_homo_nn_pipeline(config, namespace, dataset.breast, homo_nn_0, 1)
def run_homo_nn_pipeline(config, namespace, data: dict, nn_component, num_host):
if isinstance(config, str):
config = load_job_config(config)
guest_train_data = data["guest"]
host_train_data = data["host"][:num_host]
for d in [guest_train_data, *host_train_data]:
d["namespace"] = f"{d['namespace']}{namespace}"
hosts = config.parties.host[:num_host]
pipeline = (
PipeLine()
.set_initiator(role="guest", party_id=config.parties.guest[0])
.set_roles(
guest=config.parties.guest[0], host=hosts, arbiter=config.parties.arbiter
)
)
reader_0 = Reader(name="reader_0")
reader_0.get_party_instance(
role="guest", party_id=config.parties.guest[0]
).component_param(table=guest_train_data)
for i in range(num_host):
reader_0.get_party_instance(role="host", party_id=hosts[i]).component_param(
table=host_train_data[i]
)
data_transform_0 = DataTransform(name="data_transform_0", with_label=True)
data_transform_0.get_party_instance(
role="guest", party_id=config.parties.guest[0]
).component_param(with_label=True, output_format="dense")
data_transform_0.get_party_instance(role="host", party_id=hosts).component_param(
with_label=True
)
pipeline.add_component(reader_0)
pipeline.add_component(data_transform_0, data=Data(data=reader_0.output.data))
pipeline.add_component(
nn_component, data=Data(train_data=data_transform_0.output.data)
)
pipeline.compile()
pipeline.fit()
print(pipeline.get_component("homo_nn_0").get_summary())
pipeline.deploy_component([data_transform_0, nn_component])
# predict
predict_pipeline = PipeLine()
predict_pipeline.add_component(reader_0)
predict_pipeline.add_component(
pipeline,
data=Data(
predict_input={pipeline.data_transform_0.input.data: reader_0.output.data}
),
)
# run predict model
predict_pipeline.predict()
# noinspection PyPep8Naming
class dataset_meta(type):
@property
def breast(cls):
return {
"guest": {"name": "breast_homo_guest", "namespace": "experiment"},
"host": [
{"name": "breast_homo_host", "namespace": "experiment"},
{"name": "breast_homo_host", "namespace": "experiment"},
],
}
@property
def vehicle(cls):
return {
"guest": {"name": "vehicle_scale_homo_guest", "namespace": "experiment", },
"host": [
{"name": "vehicle_scale_homo_host", "namespace": "experiment"},
{"name": "vehicle_scale_homo_host", "namespace": "experiment"},
],
}
class dataset(metaclass=dataset_meta):
...
if __name__ == "__main__":
parser = argparse.ArgumentParser("PIPELINE DEMO")
parser.add_argument("-config", type=str, help="config file")
args = parser.parse_args()
if args.config is not None:
main(args.config)
else:
main()
## Homo Neural Network Configuration Usage Guide.
This section introduces the dsl and conf for usage of different type of task.
#### Training Task
- keras backend
1. single_layer:
dsl: homo_nn_dsl.json
runtime_config: keras_homo_dnn_single_layer.json
2. multi_layer:
dsl: homo_nn_dsl.json
runtime_config: keras_homo_dnn_multi_layer.json
3. multi_label and multi-host:
dsl: homo_nn_dsl.json
runtime_config: keras_homo_dnn_multi_label.json
4. multi_layer and predict
dsl: homo_nn_dsl.json
runtime_config: keras_homo_dnn_multi_layer_predict.json
- pytorch backend
1. single_layer:
dsl: homo_nn_dsl.json
runtime_config: pytorch_homo_dnn_single_layer.json
2. multi_layer:
dsl: homo_nn_dsl.json
runtime_config: pytorch_homo_dnn_multi_layer.json
3. multi_label and multi-host:
dsl: homo_nn_dsl.json
runtime_config: pytorch_homo_dnn_multi_label.json
Users can use following commands to run a task.
flow job submit -c ${runtime_config} -d ${dsl}
homo_nn_dsl.json
{
"components": {
"reader_0": {
"module": "Reader",
"output": {
"data": [
"data"
]
}
},
"data_transform_0": {
"module": "DataTransform",
"input": {
"data": {
"data": [
"reader_0.data"
]
}
},
"output": {
"data": [
"data"
],
"model": [
"model"
]
}
},
"homo_nn_0": {
"module": "HomoNN",
"input": {
"data": {
"train_data": [
"data_transform_0.data"
]
}
},
"output": {
"data": [
"data"
],
"model": [
"model"
]
}
}
}
}
pytorch_homo_nn_testsuite.json
{
"data": [
{
"file": "examples/data/breast_homo_guest.csv",
"head": 1,
"partition": 16,
"table_name": "breast_homo_guest",
"namespace": "experiment",
"role": "guest_0"
},
{
"file": "examples/data/breast_homo_host.csv",
"head": 1,
"partition": 16,
"table_name": "breast_homo_host",
"namespace": "experiment",
"role": "host_0"
},
{
"file": "examples/data/vehicle_scale_homo_guest.csv",
"head": 1,
"partition": 16,
"table_name": "vehicle_scale_homo_guest",
"namespace": "experiment",
"role": "guest_0"
},
{
"file": "examples/data/vehicle_scale_homo_host.csv",
"head": 1,
"partition": 16,
"table_name": "vehicle_scale_homo_host",
"namespace": "experiment",
"role": "host_0"
},
{
"file": "examples/data/vehicle_scale_homo_host.csv",
"head": 1,
"partition": 16,
"table_name": "vehicle_scale_homo_host",
"namespace": "experiment",
"role": "host_1"
}
],
"tasks": {
"single_layer": {
"conf": "./pytorch_homo_dnn_single_layer.json",
"dsl": "./homo_nn_dsl.json"
},
"multi_layer": {
"conf": "./pytorch_homo_dnn_multi_layer.json",
"dsl": "./homo_nn_dsl.json"
},
"multi_label": {
"conf": "./pytorch_homo_dnn_multi_label.json",
"dsl": "./homo_nn_dsl.json"
}
}
}
pytorch_homo_dnn_multi_label.json
{
"dsl_version": 2,
"initiator": {
"role": "guest",
"party_id": 9999
},
"role": {
"arbiter": [
10000
],
"host": [
10000,
9998
],
"guest": [
9999
]
},
"component_parameters": {
"common": {
"data_transform_0": {
"with_label": true
},
"homo_nn_0": {
"config_type": "pytorch",
"nn_define": [
{
"layer": "Linear",
"name": "line1",
"type": "normal",
"config": [
18,
5
]
},
{
"layer": "Relu",
"type": "activate",
"name": "relu"
},
{
"layer": "Linear",
"name": "line2",
"type": "normal",
"config": [
5,
4
]
}
],
"batch_size": -1,
"optimizer": {
"optimizer": "Adam",
"lr": 0.05
},
"early_stop": {
"early_stop": "diff",
"eps": 0.0001
},
"loss": "CrossEntropyLoss",
"metrics": [
"accuracy"
],
"max_iter": 15
}
},
"role": {
"host": {
"0": {
"reader_0": {
"table": {
"name": "vehicle_scale_homo_host",
"namespace": "experiment"
}
}
},
"1": {
"reader_0": {
"table": {
"name": "vehicle_scale_homo_host",
"namespace": "experiment"
}
}
},
"0|1": {
"data_transform_0": {
"with_label": true,
"label_name": "y",
"label_type": "int",
"output_format": "dense"
}
}
},
"guest": {
"0": {
"reader_0": {
"table": {
"name": "vehicle_scale_homo_guest",
"namespace": "experiment"
}
},
"data_transform_0": {
"with_label": true,
"output_format": "dense",
"label_name": "y",
"label_type": "int"
}
}
}
}
}
}
keras_homo_dnn_multi_label.json
{
"dsl_version": 2,
"initiator": {
"role": "guest",
"party_id": 9999
},
"role": {
"arbiter": [
10000
],
"host": [
10000,
9998
],
"guest": [
9999
]
},
"component_parameters": {
"common": {
"data_transform_0": {
"with_label": true
},
"homo_nn_0": {
"encode_label": true,
"max_iter": 15,
"batch_size": -1,
"early_stop": {
"early_stop": "diff",
"eps": 0.0001
},
"optimizer": {
"learning_rate": 0.05,
"decay": 0.0,
"beta_1": 0.9,
"beta_2": 0.999,
"epsilon": 1e-07,
"amsgrad": false,
"optimizer": "Adam"
},
"loss": "categorical_crossentropy",
"metrics": [
"accuracy"
],
"nn_define": {
"class_name": "Sequential",
"config": {
"name": "sequential",
"layers": [
{
"class_name": "Dense",
"config": {
"name": "dense",
"trainable": true,
"batch_input_shape": [
null,
18
],
"dtype": "float32",
"units": 5,
"activation": "relu",
"use_bias": true,
"kernel_initializer": {
"class_name": "GlorotUniform",
"config": {
"seed": null,
"dtype": "float32"
}
},
"bias_initializer": {
"class_name": "Zeros",
"config": {
"dtype": "float32"
}
},
"kernel_regularizer": null,
"bias_regularizer": null,
"activity_regularizer": null,
"kernel_constraint": null,
"bias_constraint": null
}
},
{
"class_name": "Dense",
"config": {
"name": "dense_1",
"trainable": true,
"dtype": "float32",
"units": 4,
"activation": "sigmoid",
"use_bias": true,
"kernel_initializer": {
"class_name": "GlorotUniform",
"config": {
"seed": null,
"dtype": "float32"
}
},
"bias_initializer": {
"class_name": "Zeros",
"config": {
"dtype": "float32"
}
},
"kernel_regularizer": null,
"bias_regularizer": null,
"activity_regularizer": null,
"kernel_constraint": null,
"bias_constraint": null
}
}
]
},
"keras_version": "2.2.4-tf",
"backend": "tensorflow"
},
"config_type": "keras"
}
},
"role": {
"host": {
"0": {
"reader_0": {
"table": {
"name": "vehicle_scale_homo_host",
"namespace": "experiment"
}
}
},
"1": {
"reader_0": {
"table": {
"name": "vehicle_scale_homo_host",
"namespace": "experiment"
}
}
},
"0|1": {
"data_transform_0": {
"with_label": true
}
}
},
"guest": {
"0": {
"reader_0": {
"table": {
"name": "vehicle_scale_homo_guest",
"namespace": "experiment"
}
},
"data_transform_0": {
"with_label": true,
"output_format": "dense"
}
}
}
}
}
}
keras_homo_dnn_multi_layer_predict.json
{
"dsl_version": 2,
"initiator": {
"role": "guest",
"party_id": 9999
},
"role": {
"arbiter": [
10000
],
"host": [
10000
],
"guest": [
9999
]
},
"job_parameters": {
"common": {
"model_id": "arbiter-10000#guest-9999#host-10000#model",
"model_version": "",
"job_type": "predict"
}
},
"component_parameters": {
"role": {
"guest": {
"0": {
"reader_0": {
"table": {
"name": "breast_homo_guest",
"namespace": "experiment"
}
}
}
},
"host": {
"0": {
"reader_0": {
"table": {
"name": "breast_homo_host",
"namespace": "experiment"
}
}
}
}
}
}
}
keras_homo_dnn_single_layer.json
{
"dsl_version": 2,
"initiator": {
"role": "guest",
"party_id": 9999
},
"role": {
"arbiter": [
10000
],
"host": [
10000
],
"guest": [
9999
]
},
"component_parameters": {
"common": {
"data_transform_0": {
"with_label": true
},
"homo_nn_0": {
"max_iter": 10,
"batch_size": -1,
"early_stop": {
"early_stop": "diff",
"eps": 0.0001
},
"optimizer": {
"learning_rate": 0.05,
"decay": 0.0,
"beta_1": 0.9,
"beta_2": 0.999,
"epsilon": 1e-07,
"amsgrad": false,
"optimizer": "Adam"
},
"loss": "binary_crossentropy",
"metrics": [
"accuracy",
"AUC"
],
"nn_define": {
"class_name": "Sequential",
"config": {
"name": "sequential",
"layers": [
{
"class_name": "Dense",
"config": {
"name": "dense",
"trainable": true,
"batch_input_shape": [
null,
10
],
"dtype": "float32",
"units": 1,
"activation": "sigmoid",
"use_bias": true,
"kernel_initializer": {
"class_name": "GlorotUniform",
"config": {
"seed": null,
"dtype": "float32"
}
},
"bias_initializer": {
"class_name": "Zeros",
"config": {
"dtype": "float32"
}
},
"kernel_regularizer": null,
"bias_regularizer": null,
"activity_regularizer": null,
"kernel_constraint": null,
"bias_constraint": null
}
}
]
},
"keras_version": "2.2.4-tf",
"backend": "tensorflow"
},
"config_type": "keras"
}
},
"role": {
"host": {
"0": {
"reader_0": {
"table": {
"name": "breast_homo_host",
"namespace": "experiment"
}
},
"data_transform_0": {
"with_label": true
}
}
},
"guest": {
"0": {
"reader_0": {
"table": {
"name": "breast_homo_guest",
"namespace": "experiment"
}
},
"data_transform_0": {
"with_label": true,
"output_format": "dense"
}
}
}
}
}
}
keras_homo_nn_testsuite.json
{
"data": [
{
"file": "examples/data/breast_homo_guest.csv",
"head": 1,
"partition": 16,
"table_name": "breast_homo_guest",
"namespace": "experiment",
"role": "guest_0"
},
{
"file": "examples/data/breast_homo_host.csv",
"head": 1,
"partition": 16,
"table_name": "breast_homo_host",
"namespace": "experiment",
"role": "host_0"
},
{
"file": "examples/data/vehicle_scale_homo_guest.csv",
"head": 1,
"partition": 16,
"table_name": "vehicle_scale_homo_guest",
"namespace": "experiment",
"role": "guest_0"
},
{
"file": "examples/data/vehicle_scale_homo_host.csv",
"head": 1,
"partition": 16,
"table_name": "vehicle_scale_homo_host",
"namespace": "experiment",
"role": "host_0"
},
{
"file": "examples/data/vehicle_scale_homo_host.csv",
"head": 1,
"partition": 16,
"table_name": "vehicle_scale_homo_host",
"namespace": "experiment",
"role": "host_1"
}
],
"tasks": {
"single_layer": {
"conf": "./keras_homo_dnn_single_layer.json",
"dsl": "./homo_nn_dsl.json"
},
"multi_layer": {
"conf": "./keras_homo_dnn_multi_layer.json",
"dsl": "./homo_nn_dsl.json"
},
"multi_label": {
"conf": "./keras_homo_dnn_multi_label.json",
"dsl": "./homo_nn_dsl.json"
},
"predict": {
"deps": "multi_layer",
"conf": "./keras_homo_dnn_multi_layer_predict.json",
"dsl": "./homo_nn_dsl.json"
}
}
}
pytorch_homo_dnn_single_layer.json
{
"dsl_version": 2,
"initiator": {
"role": "guest",
"party_id": 9999
},
"role": {
"arbiter": [
10000
],
"host": [
10000
],
"guest": [
9999
]
},
"component_parameters": {
"common": {
"data_transform_0": {
"with_label": true,
"label_name": "y",
"label_type": "int",
"output_format": "dense"
},
"homo_nn_0": {
"config_type": "pytorch",
"nn_define": [
{
"layer": "Linear",
"name": "line",
"type": "normal",
"config": [
30,
1
]
},
{
"layer": "Sigmoid",
"type": "activate",
"name": "sigmoid"
}
],
"batch_size": -1,
"optimizer": {
"optimizer": "Adam",
"lr": 0.05
},
"early_stop": {
"early_stop": "diff",
"eps": 0.0001
},
"loss": "BCELoss",
"metrics": [
"accuracy"
],
"max_iter": 2
}
},
"role": {
"host": {
"0": {
"reader_0": {
"table": {
"name": "breast_homo_host",
"namespace": "experiment"
}
}
}
},
"guest": {
"0": {
"reader_0": {
"table": {
"name": "breast_homo_guest",
"namespace": "experiment"
}
}
}
}
}
}
}
keras_homo_dnn_multi_layer.json
{
"dsl_version": 2,
"initiator": {
"role": "guest",
"party_id": 9999
},
"role": {
"arbiter": [
10000
],
"host": [
10000
],
"guest": [
9999
]
},
"component_parameters": {
"common": {
"data_transform_0": {
"with_label": true
},
"homo_nn_0": {
"max_iter": 10,
"batch_size": -1,
"early_stop": {
"early_stop": "diff",
"eps": 0.0001
},
"optimizer": {
"learning_rate": 0.05,
"decay": 0.0,
"beta_1": 0.9,
"beta_2": 0.999,
"epsilon": 1e-07,
"amsgrad": false,
"optimizer": "Adam"
},
"loss": "binary_crossentropy",
"metrics": [
"Hinge",
"accuracy",
"AUC"
],
"nn_define": {
"class_name": "Sequential",
"config": {
"name": "sequential",
"layers": [
{
"class_name": "Dense",
"config": {
"name": "dense",
"trainable": true,
"batch_input_shape": [
null,
10
],
"dtype": "float32",
"units": 6,
"activation": "relu",
"use_bias": true,
"kernel_initializer": {
"class_name": "GlorotUniform",
"config": {
"seed": null,
"dtype": "float32"
}
},
"bias_initializer": {
"class_name": "Zeros",
"config": {
"dtype": "float32"
}
},
"kernel_regularizer": null,
"bias_regularizer": null,
"activity_regularizer": null,
"kernel_constraint": null,
"bias_constraint": null
}
},
{
"class_name": "Dense",
"config": {
"name": "dense_1",
"trainable": true,
"dtype": "float32",
"units": 1,
"activation": "sigmoid",
"use_bias": true,
"kernel_initializer": {
"class_name": "GlorotUniform",
"config": {
"seed": null,
"dtype": "float32"
}
},
"bias_initializer": {
"class_name": "Zeros",
"config": {
"dtype": "float32"
}
},
"kernel_regularizer": null,
"bias_regularizer": null,
"activity_regularizer": null,
"kernel_constraint": null,
"bias_constraint": null
}
}
]
},
"keras_version": "2.2.4-tf",
"backend": "tensorflow"
},
"config_type": "keras"
}
},
"role": {
"guest": {
"0": {
"data_transform_0": {
"with_label": true,
"output_format": "dense"
},
"reader_0": {
"table": {
"name": "breast_homo_guest",
"namespace": "experiment"
}
}
}
},
"host": {
"0": {
"data_transform_0": {
"with_label": true
},
"reader_0": {
"table": {
"name": "breast_homo_host",
"namespace": "experiment"
}
}
}
}
}
}
}
pytorch_homo_dnn_multi_layer.json
{
"dsl_version": 2,
"initiator": {
"role": "guest",
"party_id": 9999
},
"role": {
"arbiter": [
10000
],
"host": [
10000
],
"guest": [
9999
]
},
"component_parameters": {
"common": {
"data_transform_0": {
"with_label": true,
"output_format": "dense",
"label_name": "y",
"label_type": "int"
},
"homo_nn_0": {
"config_type": "pytorch",
"nn_define": [
{
"layer": "Linear",
"name": "line1",
"type": "normal",
"config": [
30,
6
]
},
{
"layer": "Relu",
"type": "activate",
"name": "relu"
},
{
"layer": "Linear",
"name": "line2",
"type": "normal",
"config": [
6,
1
]
},
{
"layer": "Sigmoid",
"type": "activate",
"name": "sigmoid"
}
],
"batch_size": -1,
"optimizer": {
"optimizer": "Adam",
"lr": 0.05
},
"early_stop": {
"early_stop": "diff",
"eps": 0.0001
},
"loss": "BCELoss",
"metrics": [
"accuracy"
],
"max_iter": 5
}
},
"role": {
"host": {
"0": {
"reader_0": {
"table": {
"name": "breast_homo_host",
"namespace": "experiment"
}
}
}
},
"guest": {
"0": {
"reader_0": {
"table": {
"name": "breast_homo_guest",
"namespace": "experiment"
}
}
}
}
}
}
}