Tree Models¶
Hetero SecureBoost¶
Gradient Boosting Decision Tree(GBDT) is a widely used statistic model for classification and regression problems. FATE provides a novel lossless privacy-preserving tree-boosting system known as SecureBoost: A Lossless Federated Learning Framework.
This federated learning system allows a learning process to be jointly conducted over multiple parties with partially common user samples but different feature sets, which corresponds to a vertically partitioned data set. An advantage of SecureBoost is that it provides the same level of accuracy as the non privacy-preserving approach while revealing no information on private data.
The following figure shows the proposed Federated SecureBoost framework.
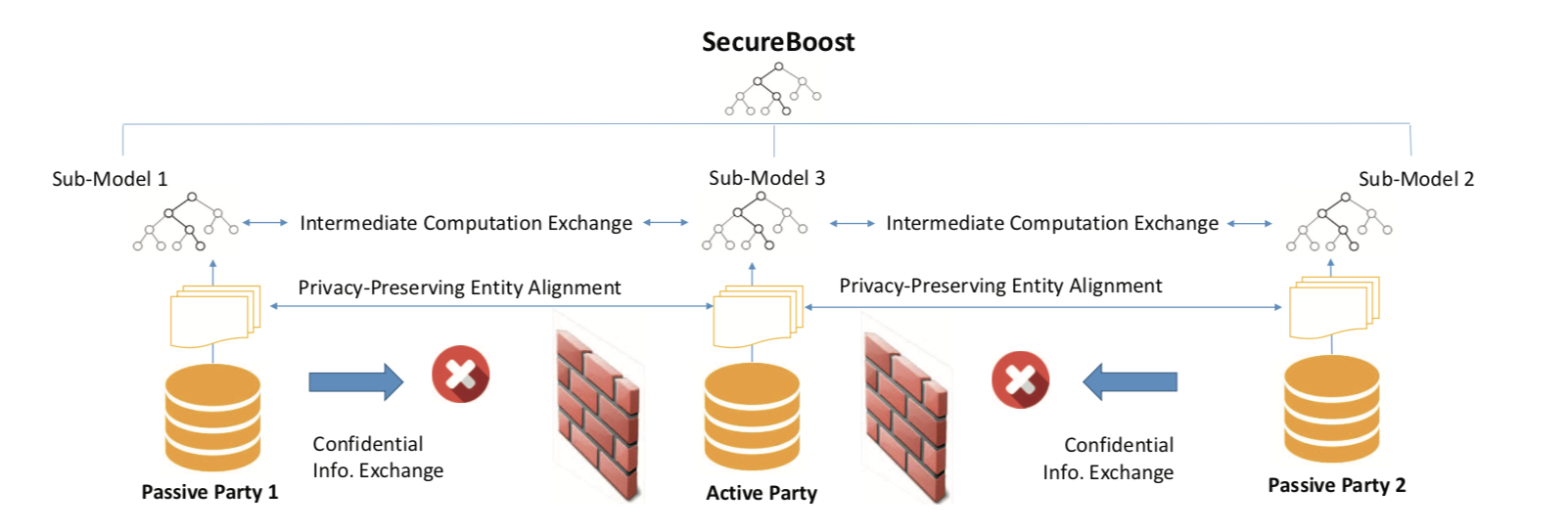
-
Active Party
We define the active party as the data provider who holds both a data matrix and the class label. Since the class label information is indispensable for supervised learning, there must be an active party with access to the label y. The active party naturally takes the responsibility as a dominating server in federated learning.
-
Passive Party
We define the data provider which has only a data matrix as a passive party. Passive parties play the role of clients in the federated learning setting. They are also in need of building a model to predict the class label y for their prediction purposes. Thus they must collaborate with the active party to build their model to predict y for their future users using their own features.
We align the data samples under an encryption scheme by using the privacy-preserving protocol for inter-database intersections to find the common shared users or data samples across the parties without compromising the non-shared parts of the user sets.
To ensure security, passive parties cannot get access to gradient and hessian directly. We use a "XGBoost" like tree-learning algorithm. In order to keep gradient and hessian confidential, we require that the active party encrypt gradient and hessian before sending them to passive parties. After encrypted the gradient and hessian, active party will send the encrypted [gradient] and [hessian] to passive party. Each passive party uses [gradient] and [hessian] to calculate the encrypted feature histograms, then encodes the (feature, split_bin_val) and constructs a (feature, split_bin_val) lookup table; it then sends the encoded value of (feature, split_bin_val) with feature histograms to the active party. After receiving the feature histograms from passive parties, the active party decrypts them and finds the best gains. If the best-gain feature belongs to a passive party, the active party sends the encoded (feature, split_bin_val) to back to the owner party. The following figure shows the process of finding split in federated tree building.
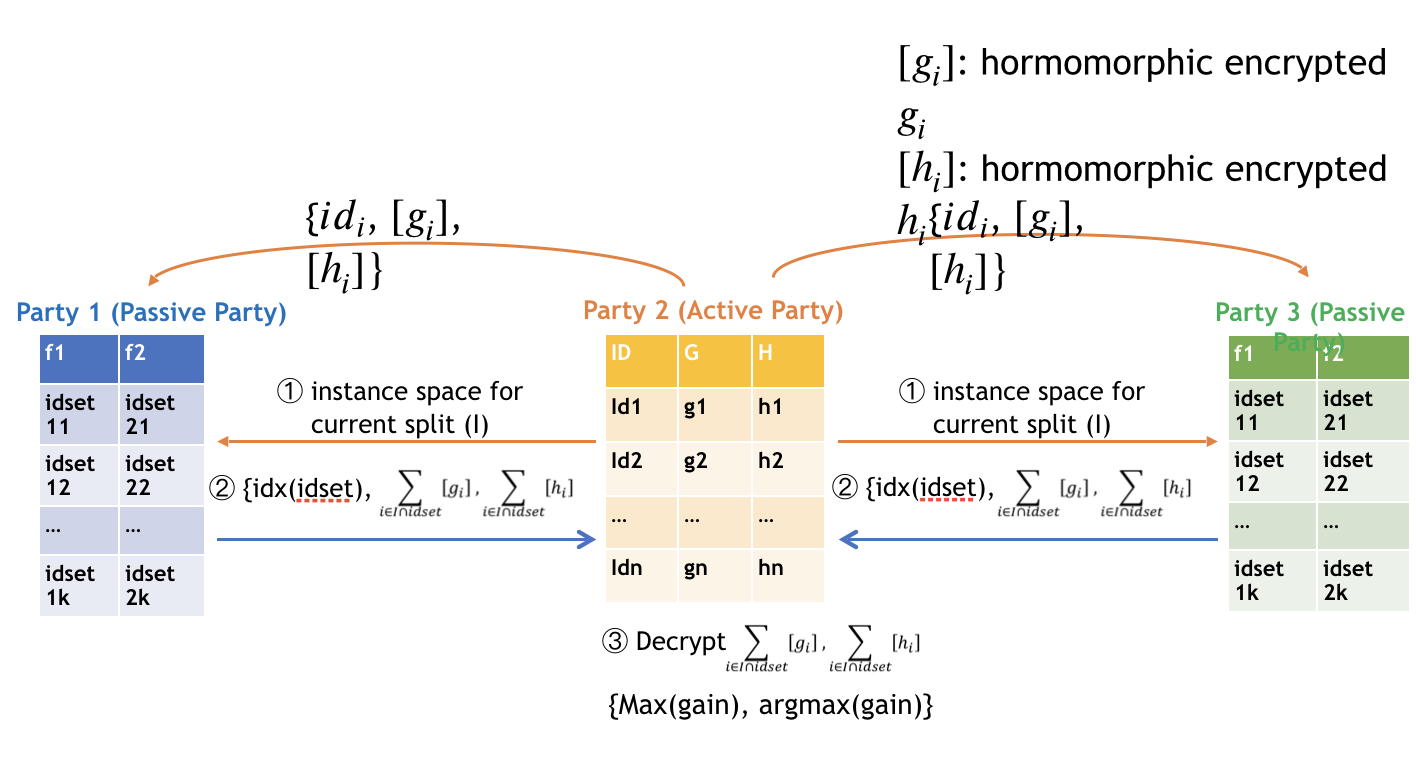
The parties continue the split finding process until tree construction finishes. Each party only knows the detailed split information of the tree nodes where the split features are provided by the party. The following figure shows the final structure of a single decision tree.
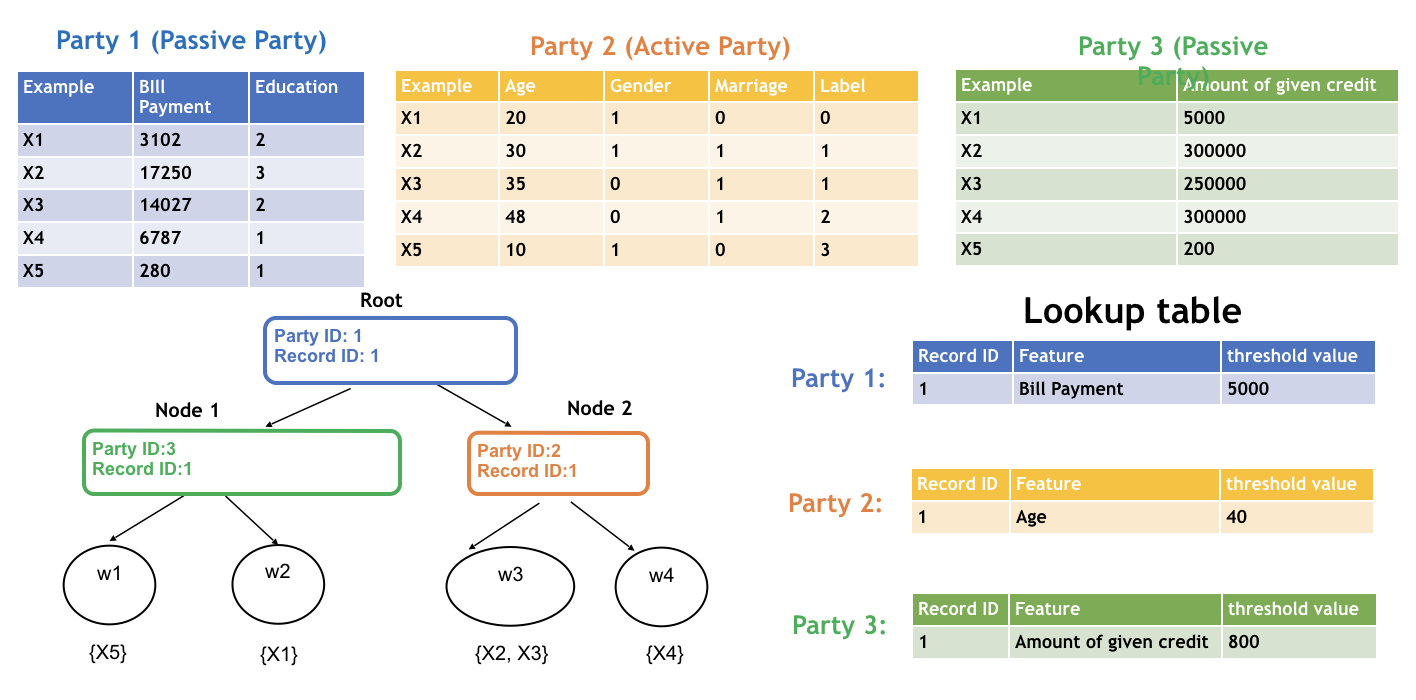
To use the learned model to classify a new instance, the active party first judges where current tree node belongs to. If the current tree belongs to the active party, then it can use its (feature, split_bin_val) lookup table to decide whether going to left child node or right; otherwise, the active party sends the node id to designated passive party, the passive party checks its lookup table and sends back which branch should the current node goes to. This process stops until the current node is a leave. The following figure shows the federated inference process.
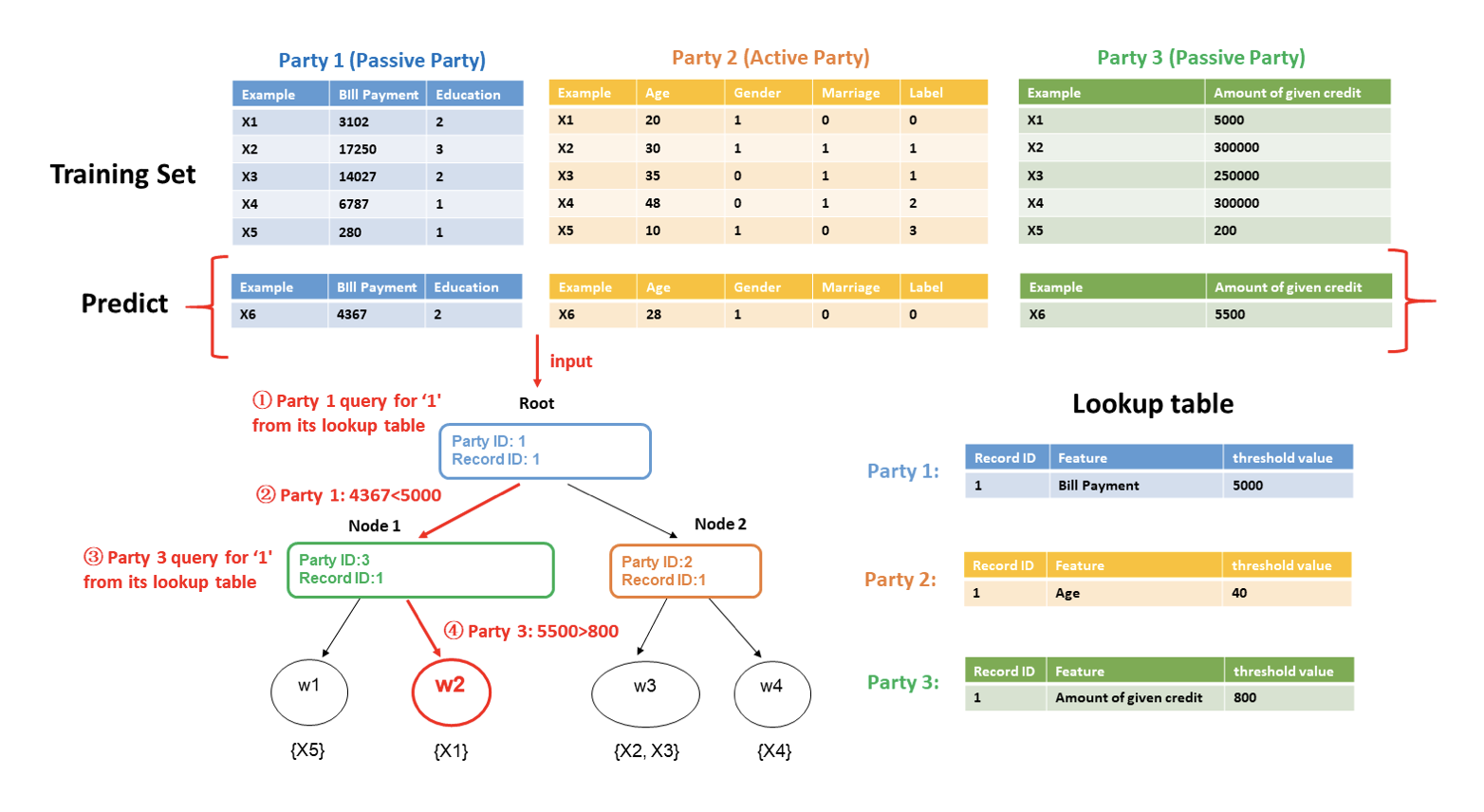
By following the SecureBoost framework, multiple parties can jointly build tree ensemble model without leaking privacy in federated learning. If you want to learn more about the algorithm, you can read the paper attached above.
Optimization in Parallel Learning¶
SecureBoost uses data parallel learning algorithm to build the decision trees in every party. The procedure of the data parallel algorithm in each party is:
- Every party use mapPartitions API interface to generate feature-histograms of each partition of data.
- Use reduce API interface to merge global histograms from all local feature-histograms
- Find the best splits from merged global histograms by federated learning, then perform splits.
Applications¶
Hetero SecureBoost supports the following applications.
- binary classification, the objective function is sigmoid cross-entropy
- multi classification, the objective function is softmax cross-entropy
- regression, objective function includes least-squared-error-loss、least-absolutely-error-loss、huber-loss、 tweedie-loss、fair-loss、 log-cosh-loss
Other features¶
- Column sub-sample
- Controlling the number of nodes to split parallelly at each layer by setting max_split_nodes parameter,in order to avoid memory limit exceeding
- Support feature importance calculation
- Support Multi-host and single guest to build model
- Support different encrypt-mode to balance speed and security
- Support missing value in train and predict process
- Support evaluate training and validate data during training process
- Support another homomorphic encryption method called "Iterative
- Support early stopping in FATE-1.4, to use early stopping, see Boosting Tree Param
- Support sparse data optimization in FATE-1.5. You can activate it by setting "sparse_optimization" as true in conf. Notice that this feature may increase memory consumption. See here.
- Support feature subsample random seed setting in FATE-1.5
- Support feature binning error setting
- Support GOSS sampling in FATE-1.6
- Support cipher compressing and g, h packing in FATE-1.7
Homo SecureBoost¶
Unlike Hetero Secureboost, Homo SecureBoost is conducted under a different setting. In homo SecureBoost, every participant(clients) holds data that shares the same feature space, and jointly train a GBDT model without leaking any data sample.
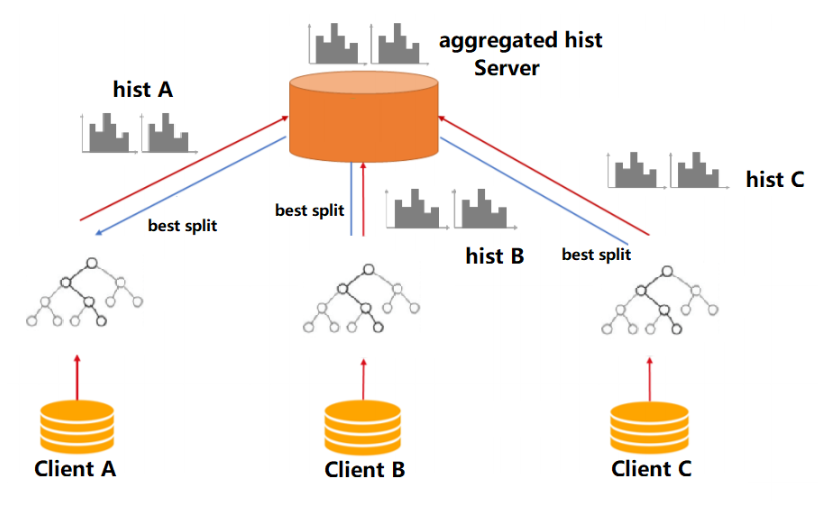
The figure below shows the overall framework of the homo SecureBoost algorithm.
-
Client
Clients are the participants who hold their labeled samples. Samples from all client parties have the same feature space. Clients are to build a more powerful model together without leaking local samples, and they share the same trained model after learning. -
Server
There are potentials of data leakage if all participants send its local histogram(which contains sum of gradient and hessian) to each other because sometimes features and labels can be inferred from gradient sums and hessian sums. Thus, to ensure security in the learning process, the Server uses secure aggregation to aggregate all participants' local histograms in a safe manner. The server can get a global histogram while not getting any local histogram and then find and broadcast the best splits to clients. Server collaborates with all clients in the learning process.
The key steps of learning a Homo SecureBoost model are described below:
- Clients and Server initialize local settings. Clients and Server apply homo feature binning to get binning points for all features and then to pre-process local samples.
-
Clients and Server build a decision tree collaboratively:
a. Clients compute local histograms for cur leaf nodes (left nodes or root node)
b. The server applies secure aggregations: every local histogram plus a random number, and these numbers can cancel each other out. By this way server can get the global histogram without knowing any local histograms and data leakage is prevented. Figure below shows how histogram secure aggregations are conducted.
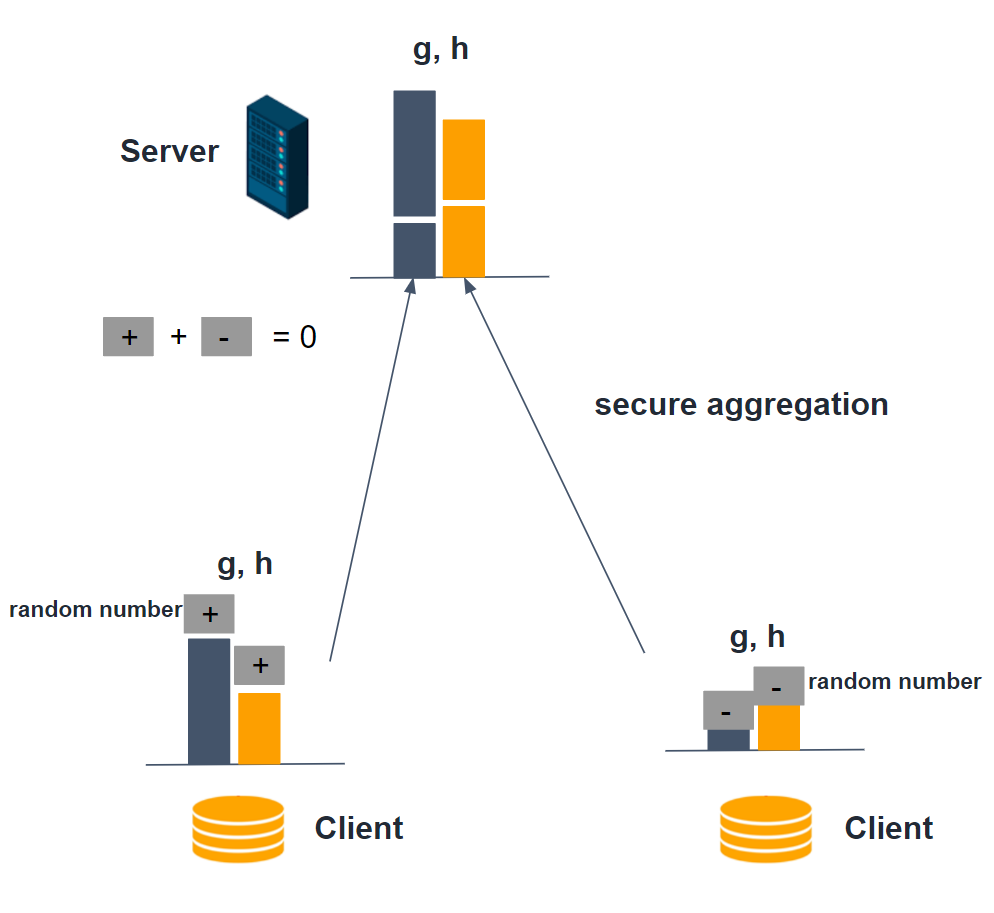
c. The server commit histogram subtractions: getting the right node histograms by subtracting left node local histogram from parent node histogram. Then, the server will find the best splits points and broadcast them to clients.
d. After getting the best split points, clients build the next layer for the current decision tree and re-assign samples. If current decision tree reaches the max depth or stop conditions are fulfilled, stop build the current tree, else go back to step (1). Figure below shows the procedure of fitting a decision tree.
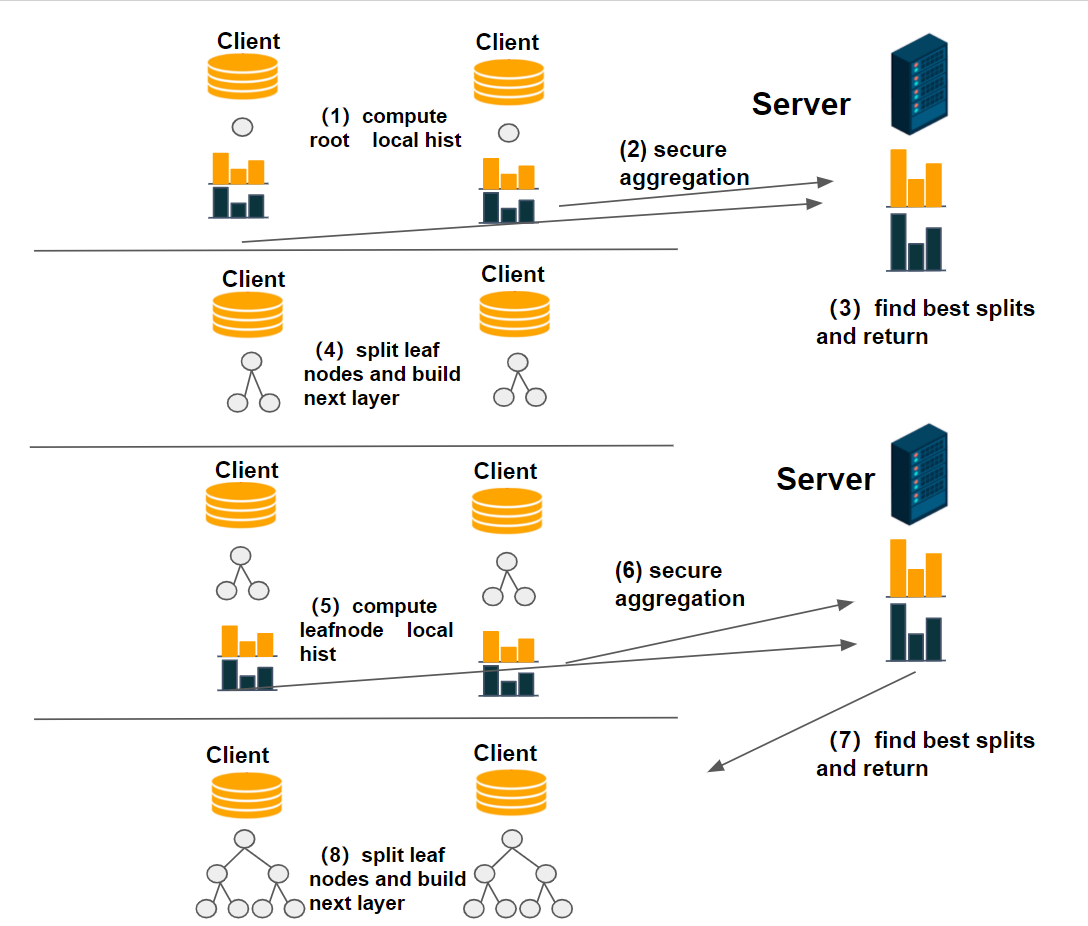
-
If tree number reaches the max number, or loss is converged, Homo SecureBoost Fitting process stops.
By following the steps above clients are able to jointly build a GBDT model. Every client can then conduct inference on a new instance locally.
Optimization in learning¶
Homo SecureBoost utilizes data parallelization and histogram subtraction to accelerate the learning process.
- Every party use mapPartitions and reduce API interface to generate local feature-histograms, only samples in left nodes are used in computing feature histograms.
- The server aggregates all local histograms to get global histograms then get sibling histograms by subtracting left node histograms from parent histograms.
- The server finds the best splits from merged global histograms, then broadcast best splits.
- The computational cost and transmission cost are halved by using node subtraction.
Applications¶
Homo SecureBoost supports the following applications:
- binary classification, the objective function is sigmoid cross-entropy
- multi classification, the objective function is softmax cross-entropy
- regression, objective function includes least-squared-error-loss, least-absolutely-error-loss, huber-loss, tweedie-loss, fair-loss, log-cosh-loss
Other features¶
- Server uses safe aggregations to aggregate clients' histograms and losses, ensuring data security
- Column sub-sample
- Controlling the number of nodes to split parallelly at each layer by setting max_split_nodes parameter,in order to avoid memory limit exceeding
- Support feature importance calculation
- Support Multi-host and single guest to build model
- Support missing value in train and predict process
- Support evaluate training and validate data during training process
- Support feature subsample random seed setting in FATE-1.5
- Support feature binning error setting.
Param¶
boosting_param
¶
hetero_deprecated_param_list
¶
homo_deprecated_param_list
¶
Classes¶
ObjectiveParam (BaseParam)
¶
Define objective parameters that used in federated ml.
Parameters:
| Name | Type | Description | Default |
|---|---|---|---|
objective |
{None, 'cross_entropy', 'lse', 'lae', 'log_cosh', 'tweedie', 'fair', 'huber'} |
None in host's config, should be str in guest'config. when task_type is classification, only support 'cross_entropy', other 6 types support in regression task |
'cross_entropy' |
params |
None or list |
should be non empty list when objective is 'tweedie','fair','huber', first element of list shoulf be a float-number large than 0.0 when objective is 'fair', 'huber', first element of list should be a float-number in [1.0, 2.0) when objective is 'tweedie' |
None |
Source code in federatedml/param/boosting_param.py
class ObjectiveParam(BaseParam):
"""
Define objective parameters that used in federated ml.
Parameters
----------
objective : {None, 'cross_entropy', 'lse', 'lae', 'log_cosh', 'tweedie', 'fair', 'huber'}
None in host's config, should be str in guest'config.
when task_type is classification, only support 'cross_entropy',
other 6 types support in regression task
params : None or list
should be non empty list when objective is 'tweedie','fair','huber',
first element of list shoulf be a float-number large than 0.0 when objective is 'fair', 'huber',
first element of list should be a float-number in [1.0, 2.0) when objective is 'tweedie'
"""
def __init__(self, objective='cross_entropy', params=None):
self.objective = objective
self.params = params
def check(self, task_type=None):
if self.objective is None:
return True
descr = "objective param's"
LOGGER.debug('check objective {}'.format(self.objective))
if task_type not in [consts.CLASSIFICATION, consts.REGRESSION]:
self.objective = self.check_and_change_lower(self.objective,
["cross_entropy", "lse", "lae", "huber", "fair",
"log_cosh", "tweedie"],
descr)
if task_type == consts.CLASSIFICATION:
if self.objective != "cross_entropy":
raise ValueError("objective param's objective {} not supported".format(self.objective))
elif task_type == consts.REGRESSION:
self.objective = self.check_and_change_lower(self.objective,
["lse", "lae", "huber", "fair", "log_cosh", "tweedie"],
descr)
params = self.params
if self.objective in ["huber", "fair", "tweedie"]:
if type(params).__name__ != 'list' or len(params) < 1:
raise ValueError(
"objective param's params {} not supported, should be non-empty list".format(params))
if type(params[0]).__name__ not in ["float", "int", "long"]:
raise ValueError("objective param's params[0] {} not supported".format(self.params[0]))
if self.objective == 'tweedie':
if params[0] < 1 or params[0] >= 2:
raise ValueError("in tweedie regression, objective params[0] should betweend [1, 2)")
if self.objective == 'fair' or 'huber':
if params[0] <= 0.0:
raise ValueError("in {} regression, objective params[0] should greater than 0.0".format(
self.objective))
return True
__init__(self, objective='cross_entropy', params=None)
special
¶Source code in federatedml/param/boosting_param.py
def __init__(self, objective='cross_entropy', params=None):
self.objective = objective
self.params = params
check(self, task_type=None)
¶Source code in federatedml/param/boosting_param.py
def check(self, task_type=None):
if self.objective is None:
return True
descr = "objective param's"
LOGGER.debug('check objective {}'.format(self.objective))
if task_type not in [consts.CLASSIFICATION, consts.REGRESSION]:
self.objective = self.check_and_change_lower(self.objective,
["cross_entropy", "lse", "lae", "huber", "fair",
"log_cosh", "tweedie"],
descr)
if task_type == consts.CLASSIFICATION:
if self.objective != "cross_entropy":
raise ValueError("objective param's objective {} not supported".format(self.objective))
elif task_type == consts.REGRESSION:
self.objective = self.check_and_change_lower(self.objective,
["lse", "lae", "huber", "fair", "log_cosh", "tweedie"],
descr)
params = self.params
if self.objective in ["huber", "fair", "tweedie"]:
if type(params).__name__ != 'list' or len(params) < 1:
raise ValueError(
"objective param's params {} not supported, should be non-empty list".format(params))
if type(params[0]).__name__ not in ["float", "int", "long"]:
raise ValueError("objective param's params[0] {} not supported".format(self.params[0]))
if self.objective == 'tweedie':
if params[0] < 1 or params[0] >= 2:
raise ValueError("in tweedie regression, objective params[0] should betweend [1, 2)")
if self.objective == 'fair' or 'huber':
if params[0] <= 0.0:
raise ValueError("in {} regression, objective params[0] should greater than 0.0".format(
self.objective))
return True
DecisionTreeParam (BaseParam)
¶
Define decision tree parameters that used in federated ml.
Parameters:
| Name | Type | Description | Default |
|---|---|---|---|
criterion_method |
{"xgboost"}, default: "xgboost" |
the criterion function to use |
'xgboost' |
criterion_params |
list or dict |
should be non empty and elements are float-numbers, if a list is offered, the first one is l2 regularization value, and the second one is l1 regularization value. if a dict is offered, make sure it contains key 'l1', and 'l2'. l1, l2 regularization values are non-negative floats. default: [0.1, 0] or {'l1':0, 'l2':0,1} |
[0.1, 0] |
max_depth |
positive integer |
the max depth of a decision tree, default: 3 |
3 |
min_sample_split |
int |
least quantity of nodes to split, default: 2 |
2 |
min_impurity_split |
float |
least gain of a single split need to reach, default: 1e-3 |
0.001 |
min_child_weight |
float |
sum of hessian needed in child nodes. default is 0 |
0 |
min_leaf_node |
int |
when samples no more than min_leaf_node, it becomes a leave, default: 1 |
1 |
max_split_nodes |
positive integer |
we will use no more than max_split_nodes to parallel finding their splits in a batch, for memory consideration. default is 65536 |
65536 |
feature_importance_type |
{'split', 'gain'} |
if is 'split', feature_importances calculate by feature split times, if is 'gain', feature_importances calculate by feature split gain. default: 'split' |
'split' |
use_missing |
bool |
use missing value in training process or not. default: False |
False |
zero_as_missing |
bool |
regard 0 as missing value or not, will be use only if use_missing=True, default: False |
False |
deterministic |
bool |
ensure stability when computing histogram. Set this to true to ensure stable result when using same data and same parameter. But it may slow down computation. |
False |
Source code in federatedml/param/boosting_param.py
class DecisionTreeParam(BaseParam):
"""
Define decision tree parameters that used in federated ml.
Parameters
----------
criterion_method : {"xgboost"}, default: "xgboost"
the criterion function to use
criterion_params: list or dict
should be non empty and elements are float-numbers,
if a list is offered, the first one is l2 regularization value, and the second one is
l1 regularization value.
if a dict is offered, make sure it contains key 'l1', and 'l2'.
l1, l2 regularization values are non-negative floats.
default: [0.1, 0] or {'l1':0, 'l2':0,1}
max_depth: positive integer
the max depth of a decision tree, default: 3
min_sample_split: int
least quantity of nodes to split, default: 2
min_impurity_split: float
least gain of a single split need to reach, default: 1e-3
min_child_weight: float
sum of hessian needed in child nodes. default is 0
min_leaf_node: int
when samples no more than min_leaf_node, it becomes a leave, default: 1
max_split_nodes: positive integer
we will use no more than max_split_nodes to
parallel finding their splits in a batch, for memory consideration. default is 65536
feature_importance_type: {'split', 'gain'}
if is 'split', feature_importances calculate by feature split times,
if is 'gain', feature_importances calculate by feature split gain.
default: 'split'
use_missing: bool
use missing value in training process or not. default: False
zero_as_missing: bool
regard 0 as missing value or not,
will be use only if use_missing=True, default: False
deterministic: bool
ensure stability when computing histogram. Set this to true to ensure stable result when using
same data and same parameter. But it may slow down computation.
"""
def __init__(self, criterion_method="xgboost", criterion_params=[0.1, 0], max_depth=3,
min_sample_split=2, min_impurity_split=1e-3, min_leaf_node=1,
max_split_nodes=consts.MAX_SPLIT_NODES, feature_importance_type="split",
n_iter_no_change=True, tol=0.001, min_child_weight=0,
use_missing=False, zero_as_missing=False, deterministic=False):
super(DecisionTreeParam, self).__init__()
self.criterion_method = criterion_method
self.criterion_params = criterion_params
self.max_depth = max_depth
self.min_sample_split = min_sample_split
self.min_impurity_split = min_impurity_split
self.min_leaf_node = min_leaf_node
self.min_child_weight = min_child_weight
self.max_split_nodes = max_split_nodes
self.feature_importance_type = feature_importance_type
self.n_iter_no_change = n_iter_no_change
self.tol = tol
self.use_missing = use_missing
self.zero_as_missing = zero_as_missing
self.deterministic = deterministic
def check(self):
descr = "decision tree param"
self.criterion_method = self.check_and_change_lower(self.criterion_method,
["xgboost"],
descr)
if len(self.criterion_params) == 0:
raise ValueError("decisition tree param's criterio_params should be non empty")
if type(self.criterion_params) == list:
assert len(self.criterion_params) == 2, 'length of criterion_param should be 2: l1, l2 regularization ' \
'values are needed'
self.check_nonnegative_number(self.criterion_params[0], 'l2 reg value')
self.check_nonnegative_number(self.criterion_params[1], 'l1 reg value')
elif type(self.criterion_params) == dict:
assert 'l1' in self.criterion_params and 'l2' in self.criterion_params, 'l1 and l2 keys are needed in ' \
'criterion_params dict'
self.criterion_params = [self.criterion_params['l2'], self.criterion_params['l1']]
else:
raise ValueError('criterion_params should be a dict or a list contains l1, l2 reg value')
if type(self.max_depth).__name__ not in ["int", "long"]:
raise ValueError("decision tree param's max_depth {} not supported, should be integer".format(
self.max_depth))
if self.max_depth < 1:
raise ValueError("decision tree param's max_depth should be positive integer, no less than 1")
if type(self.min_sample_split).__name__ not in ["int", "long"]:
raise ValueError("decision tree param's min_sample_split {} not supported, should be integer".format(
self.min_sample_split))
if type(self.min_impurity_split).__name__ not in ["int", "long", "float"]:
raise ValueError("decision tree param's min_impurity_split {} not supported, should be numeric".format(
self.min_impurity_split))
if type(self.min_leaf_node).__name__ not in ["int", "long"]:
raise ValueError("decision tree param's min_leaf_node {} not supported, should be integer".format(
self.min_leaf_node))
if type(self.max_split_nodes).__name__ not in ["int", "long"] or self.max_split_nodes < 1:
raise ValueError("decision tree param's max_split_nodes {} not supported, " + \
"should be positive integer between 1 and {}".format(self.max_split_nodes,
consts.MAX_SPLIT_NODES))
if type(self.n_iter_no_change).__name__ != "bool":
raise ValueError("decision tree param's n_iter_no_change {} not supported, should be bool type".format(
self.n_iter_no_change))
if type(self.tol).__name__ not in ["float", "int", "long"]:
raise ValueError("decision tree param's tol {} not supported, should be numeric".format(self.tol))
self.feature_importance_type = self.check_and_change_lower(self.feature_importance_type,
["split", "gain"],
descr)
self.check_nonnegative_number(self.min_child_weight, 'min_child_weight')
self.check_boolean(self.deterministic, 'deterministic')
return True
__init__(self, criterion_method='xgboost', criterion_params=[0.1, 0], max_depth=3, min_sample_split=2, min_impurity_split=0.001, min_leaf_node=1, max_split_nodes=65536, feature_importance_type='split', n_iter_no_change=True, tol=0.001, min_child_weight=0, use_missing=False, zero_as_missing=False, deterministic=False)
special
¶Source code in federatedml/param/boosting_param.py
def __init__(self, criterion_method="xgboost", criterion_params=[0.1, 0], max_depth=3,
min_sample_split=2, min_impurity_split=1e-3, min_leaf_node=1,
max_split_nodes=consts.MAX_SPLIT_NODES, feature_importance_type="split",
n_iter_no_change=True, tol=0.001, min_child_weight=0,
use_missing=False, zero_as_missing=False, deterministic=False):
super(DecisionTreeParam, self).__init__()
self.criterion_method = criterion_method
self.criterion_params = criterion_params
self.max_depth = max_depth
self.min_sample_split = min_sample_split
self.min_impurity_split = min_impurity_split
self.min_leaf_node = min_leaf_node
self.min_child_weight = min_child_weight
self.max_split_nodes = max_split_nodes
self.feature_importance_type = feature_importance_type
self.n_iter_no_change = n_iter_no_change
self.tol = tol
self.use_missing = use_missing
self.zero_as_missing = zero_as_missing
self.deterministic = deterministic
check(self)
¶Source code in federatedml/param/boosting_param.py
def check(self):
descr = "decision tree param"
self.criterion_method = self.check_and_change_lower(self.criterion_method,
["xgboost"],
descr)
if len(self.criterion_params) == 0:
raise ValueError("decisition tree param's criterio_params should be non empty")
if type(self.criterion_params) == list:
assert len(self.criterion_params) == 2, 'length of criterion_param should be 2: l1, l2 regularization ' \
'values are needed'
self.check_nonnegative_number(self.criterion_params[0], 'l2 reg value')
self.check_nonnegative_number(self.criterion_params[1], 'l1 reg value')
elif type(self.criterion_params) == dict:
assert 'l1' in self.criterion_params and 'l2' in self.criterion_params, 'l1 and l2 keys are needed in ' \
'criterion_params dict'
self.criterion_params = [self.criterion_params['l2'], self.criterion_params['l1']]
else:
raise ValueError('criterion_params should be a dict or a list contains l1, l2 reg value')
if type(self.max_depth).__name__ not in ["int", "long"]:
raise ValueError("decision tree param's max_depth {} not supported, should be integer".format(
self.max_depth))
if self.max_depth < 1:
raise ValueError("decision tree param's max_depth should be positive integer, no less than 1")
if type(self.min_sample_split).__name__ not in ["int", "long"]:
raise ValueError("decision tree param's min_sample_split {} not supported, should be integer".format(
self.min_sample_split))
if type(self.min_impurity_split).__name__ not in ["int", "long", "float"]:
raise ValueError("decision tree param's min_impurity_split {} not supported, should be numeric".format(
self.min_impurity_split))
if type(self.min_leaf_node).__name__ not in ["int", "long"]:
raise ValueError("decision tree param's min_leaf_node {} not supported, should be integer".format(
self.min_leaf_node))
if type(self.max_split_nodes).__name__ not in ["int", "long"] or self.max_split_nodes < 1:
raise ValueError("decision tree param's max_split_nodes {} not supported, " + \
"should be positive integer between 1 and {}".format(self.max_split_nodes,
consts.MAX_SPLIT_NODES))
if type(self.n_iter_no_change).__name__ != "bool":
raise ValueError("decision tree param's n_iter_no_change {} not supported, should be bool type".format(
self.n_iter_no_change))
if type(self.tol).__name__ not in ["float", "int", "long"]:
raise ValueError("decision tree param's tol {} not supported, should be numeric".format(self.tol))
self.feature_importance_type = self.check_and_change_lower(self.feature_importance_type,
["split", "gain"],
descr)
self.check_nonnegative_number(self.min_child_weight, 'min_child_weight')
self.check_boolean(self.deterministic, 'deterministic')
return True
BoostingParam (BaseParam)
¶
Basic parameter for Boosting Algorithms
Parameters:
| Name | Type | Description | Default |
|---|---|---|---|
task_type |
{'classification', 'regression'}, default: 'classification' |
task type |
'classification' |
objective_param |
ObjectiveParam Object, default: ObjectiveParam() |
objective param |
<federatedml.param.boosting_param.ObjectiveParam object at 0x7ff45d9b7510> |
learning_rate |
float, int or long |
the learning rate of secure boost. default: 0.3 |
0.3 |
num_trees |
int or float |
the max number of boosting round. default: 5 |
5 |
subsample_feature_rate |
float |
a float-number in [0, 1], default: 1.0 |
1 |
n_iter_no_change |
bool, |
when True and residual error less than tol, tree building process will stop. default: True |
True |
bin_num |
positive integer greater than 1 |
bin number use in quantile. default: 32 |
32 |
validation_freqs |
None or positive integer or container object in python |
Do validation in training process or Not. if equals None, will not do validation in train process; if equals positive integer, will validate data every validation_freqs epochs passes; if container object in python, will validate data if epochs belong to this container. e.g. validation_freqs = [10, 15], will validate data when epoch equals to 10 and 15. Default: None |
None |
Source code in federatedml/param/boosting_param.py
class BoostingParam(BaseParam):
"""
Basic parameter for Boosting Algorithms
Parameters
----------
task_type : {'classification', 'regression'}, default: 'classification'
task type
objective_param : ObjectiveParam Object, default: ObjectiveParam()
objective param
learning_rate : float, int or long
the learning rate of secure boost. default: 0.3
num_trees : int or float
the max number of boosting round. default: 5
subsample_feature_rate : float
a float-number in [0, 1], default: 1.0
n_iter_no_change : bool,
when True and residual error less than tol, tree building process will stop. default: True
bin_num: positive integer greater than 1
bin number use in quantile. default: 32
validation_freqs: None or positive integer or container object in python
Do validation in training process or Not.
if equals None, will not do validation in train process;
if equals positive integer, will validate data every validation_freqs epochs passes;
if container object in python, will validate data if epochs belong to this container.
e.g. validation_freqs = [10, 15], will validate data when epoch equals to 10 and 15.
Default: None
"""
def __init__(self, task_type=consts.CLASSIFICATION,
objective_param=ObjectiveParam(),
learning_rate=0.3, num_trees=5, subsample_feature_rate=1, n_iter_no_change=True,
tol=0.0001, bin_num=32,
predict_param=PredictParam(), cv_param=CrossValidationParam(),
validation_freqs=None, metrics=None, random_seed=100,
binning_error=consts.DEFAULT_RELATIVE_ERROR):
super(BoostingParam, self).__init__()
self.task_type = task_type
self.objective_param = copy.deepcopy(objective_param)
self.learning_rate = learning_rate
self.num_trees = num_trees
self.subsample_feature_rate = subsample_feature_rate
self.n_iter_no_change = n_iter_no_change
self.tol = tol
self.bin_num = bin_num
self.predict_param = copy.deepcopy(predict_param)
self.cv_param = copy.deepcopy(cv_param)
self.validation_freqs = validation_freqs
self.metrics = metrics
self.random_seed = random_seed
self.binning_error = binning_error
def check(self):
descr = "boosting tree param's"
if self.task_type not in [consts.CLASSIFICATION, consts.REGRESSION]:
raise ValueError("boosting_core tree param's task_type {} not supported, should be {} or {}".format(
self.task_type, consts.CLASSIFICATION, consts.REGRESSION))
self.objective_param.check(self.task_type)
if type(self.learning_rate).__name__ not in ["float", "int", "long"]:
raise ValueError("boosting_core tree param's learning_rate {} not supported, should be numeric".format(
self.learning_rate))
if type(self.subsample_feature_rate).__name__ not in ["float", "int", "long"] or \
self.subsample_feature_rate < 0 or self.subsample_feature_rate > 1:
raise ValueError("boosting_core tree param's subsample_feature_rate should be a numeric number between 0 and 1")
if type(self.n_iter_no_change).__name__ != "bool":
raise ValueError("boosting_core tree param's n_iter_no_change {} not supported, should be bool type".format(
self.n_iter_no_change))
if type(self.tol).__name__ not in ["float", "int", "long"]:
raise ValueError("boosting_core tree param's tol {} not supported, should be numeric".format(self.tol))
if type(self.bin_num).__name__ not in ["int", "long"] or self.bin_num < 2:
raise ValueError(
"boosting_core tree param's bin_num {} not supported, should be positive integer greater than 1".format(
self.bin_num))
if self.validation_freqs is None:
pass
elif isinstance(self.validation_freqs, int):
if self.validation_freqs < 1:
raise ValueError("validation_freqs should be larger than 0 when it's integer")
elif not isinstance(self.validation_freqs, collections.Container):
raise ValueError("validation_freqs should be None or positive integer or container")
if self.metrics is not None and not isinstance(self.metrics, list):
raise ValueError("metrics should be a list")
if self.random_seed is not None:
assert type(self.random_seed) == int and self.random_seed >= 0, 'random seed must be an integer >= 0'
self.check_decimal_float(self.binning_error, descr)
return True
__init__(self, task_type='classification', objective_param=<federatedml.param.boosting_param.ObjectiveParam object at 0x7ff45d9b7510>, learning_rate=0.3, num_trees=5, subsample_feature_rate=1, n_iter_no_change=True, tol=0.0001, bin_num=32, predict_param=<federatedml.param.predict_param.PredictParam object at 0x7ff45d9b7610>, cv_param=<federatedml.param.cross_validation_param.CrossValidationParam object at 0x7ff45d9b7710>, validation_freqs=None, metrics=None, random_seed=100, binning_error=0.0001)
special
¶Source code in federatedml/param/boosting_param.py
def __init__(self, task_type=consts.CLASSIFICATION,
objective_param=ObjectiveParam(),
learning_rate=0.3, num_trees=5, subsample_feature_rate=1, n_iter_no_change=True,
tol=0.0001, bin_num=32,
predict_param=PredictParam(), cv_param=CrossValidationParam(),
validation_freqs=None, metrics=None, random_seed=100,
binning_error=consts.DEFAULT_RELATIVE_ERROR):
super(BoostingParam, self).__init__()
self.task_type = task_type
self.objective_param = copy.deepcopy(objective_param)
self.learning_rate = learning_rate
self.num_trees = num_trees
self.subsample_feature_rate = subsample_feature_rate
self.n_iter_no_change = n_iter_no_change
self.tol = tol
self.bin_num = bin_num
self.predict_param = copy.deepcopy(predict_param)
self.cv_param = copy.deepcopy(cv_param)
self.validation_freqs = validation_freqs
self.metrics = metrics
self.random_seed = random_seed
self.binning_error = binning_error
check(self)
¶Source code in federatedml/param/boosting_param.py
def check(self):
descr = "boosting tree param's"
if self.task_type not in [consts.CLASSIFICATION, consts.REGRESSION]:
raise ValueError("boosting_core tree param's task_type {} not supported, should be {} or {}".format(
self.task_type, consts.CLASSIFICATION, consts.REGRESSION))
self.objective_param.check(self.task_type)
if type(self.learning_rate).__name__ not in ["float", "int", "long"]:
raise ValueError("boosting_core tree param's learning_rate {} not supported, should be numeric".format(
self.learning_rate))
if type(self.subsample_feature_rate).__name__ not in ["float", "int", "long"] or \
self.subsample_feature_rate < 0 or self.subsample_feature_rate > 1:
raise ValueError("boosting_core tree param's subsample_feature_rate should be a numeric number between 0 and 1")
if type(self.n_iter_no_change).__name__ != "bool":
raise ValueError("boosting_core tree param's n_iter_no_change {} not supported, should be bool type".format(
self.n_iter_no_change))
if type(self.tol).__name__ not in ["float", "int", "long"]:
raise ValueError("boosting_core tree param's tol {} not supported, should be numeric".format(self.tol))
if type(self.bin_num).__name__ not in ["int", "long"] or self.bin_num < 2:
raise ValueError(
"boosting_core tree param's bin_num {} not supported, should be positive integer greater than 1".format(
self.bin_num))
if self.validation_freqs is None:
pass
elif isinstance(self.validation_freqs, int):
if self.validation_freqs < 1:
raise ValueError("validation_freqs should be larger than 0 when it's integer")
elif not isinstance(self.validation_freqs, collections.Container):
raise ValueError("validation_freqs should be None or positive integer or container")
if self.metrics is not None and not isinstance(self.metrics, list):
raise ValueError("metrics should be a list")
if self.random_seed is not None:
assert type(self.random_seed) == int and self.random_seed >= 0, 'random seed must be an integer >= 0'
self.check_decimal_float(self.binning_error, descr)
return True
HeteroBoostingParam (BoostingParam)
¶
Parameters:
| Name | Type | Description | Default |
|---|---|---|---|
encrypt_param |
EncodeParam Object |
encrypt method use in secure boost, default: EncryptParam() |
<federatedml.param.encrypt_param.EncryptParam object at 0x7ff45d9b77d0> |
encrypted_mode_calculator_param |
EncryptedModeCalculatorParam object |
the calculation mode use in secureboost, default: EncryptedModeCalculatorParam() |
<federatedml.param.encrypted_mode_calculation_param.EncryptedModeCalculatorParam object at 0x7ff45d9b7890> |
Source code in federatedml/param/boosting_param.py
class HeteroBoostingParam(BoostingParam):
"""
Parameters
----------
encrypt_param : EncodeParam Object
encrypt method use in secure boost, default: EncryptParam()
encrypted_mode_calculator_param: EncryptedModeCalculatorParam object
the calculation mode use in secureboost,
default: EncryptedModeCalculatorParam()
"""
def __init__(self, task_type=consts.CLASSIFICATION,
objective_param=ObjectiveParam(),
learning_rate=0.3, num_trees=5, subsample_feature_rate=1, n_iter_no_change=True,
tol=0.0001, encrypt_param=EncryptParam(),
bin_num=32,
encrypted_mode_calculator_param=EncryptedModeCalculatorParam(),
predict_param=PredictParam(), cv_param=CrossValidationParam(),
validation_freqs=None, early_stopping_rounds=None, metrics=None, use_first_metric_only=False,
random_seed=100, binning_error=consts.DEFAULT_RELATIVE_ERROR):
super(HeteroBoostingParam, self).__init__(task_type, objective_param, learning_rate, num_trees,
subsample_feature_rate, n_iter_no_change, tol, bin_num,
predict_param, cv_param, validation_freqs, metrics=metrics,
random_seed=random_seed,
binning_error=binning_error)
self.encrypt_param = copy.deepcopy(encrypt_param)
self.encrypted_mode_calculator_param = copy.deepcopy(encrypted_mode_calculator_param)
self.early_stopping_rounds = early_stopping_rounds
self.use_first_metric_only = use_first_metric_only
def check(self):
super(HeteroBoostingParam, self).check()
self.encrypted_mode_calculator_param.check()
self.encrypt_param.check()
if self.early_stopping_rounds is None:
pass
elif isinstance(self.early_stopping_rounds, int):
if self.early_stopping_rounds < 1:
raise ValueError("early stopping rounds should be larger than 0 when it's integer")
if self.validation_freqs is None:
raise ValueError("validation freqs must be set when early stopping is enabled")
if not isinstance(self.use_first_metric_only, bool):
raise ValueError("use_first_metric_only should be a boolean")
return True
__init__(self, task_type='classification', objective_param=<federatedml.param.boosting_param.ObjectiveParam object at 0x7ff45d9b76d0>, learning_rate=0.3, num_trees=5, subsample_feature_rate=1, n_iter_no_change=True, tol=0.0001, encrypt_param=<federatedml.param.encrypt_param.EncryptParam object at 0x7ff45d9b77d0>, bin_num=32, encrypted_mode_calculator_param=<federatedml.param.encrypted_mode_calculation_param.EncryptedModeCalculatorParam object at 0x7ff45d9b7890>, predict_param=<federatedml.param.predict_param.PredictParam object at 0x7ff45d9b7690>, cv_param=<federatedml.param.cross_validation_param.CrossValidationParam object at 0x7ff45d9b7810>, validation_freqs=None, early_stopping_rounds=None, metrics=None, use_first_metric_only=False, random_seed=100, binning_error=0.0001)
special
¶Source code in federatedml/param/boosting_param.py
def __init__(self, task_type=consts.CLASSIFICATION,
objective_param=ObjectiveParam(),
learning_rate=0.3, num_trees=5, subsample_feature_rate=1, n_iter_no_change=True,
tol=0.0001, encrypt_param=EncryptParam(),
bin_num=32,
encrypted_mode_calculator_param=EncryptedModeCalculatorParam(),
predict_param=PredictParam(), cv_param=CrossValidationParam(),
validation_freqs=None, early_stopping_rounds=None, metrics=None, use_first_metric_only=False,
random_seed=100, binning_error=consts.DEFAULT_RELATIVE_ERROR):
super(HeteroBoostingParam, self).__init__(task_type, objective_param, learning_rate, num_trees,
subsample_feature_rate, n_iter_no_change, tol, bin_num,
predict_param, cv_param, validation_freqs, metrics=metrics,
random_seed=random_seed,
binning_error=binning_error)
self.encrypt_param = copy.deepcopy(encrypt_param)
self.encrypted_mode_calculator_param = copy.deepcopy(encrypted_mode_calculator_param)
self.early_stopping_rounds = early_stopping_rounds
self.use_first_metric_only = use_first_metric_only
check(self)
¶Source code in federatedml/param/boosting_param.py
def check(self):
super(HeteroBoostingParam, self).check()
self.encrypted_mode_calculator_param.check()
self.encrypt_param.check()
if self.early_stopping_rounds is None:
pass
elif isinstance(self.early_stopping_rounds, int):
if self.early_stopping_rounds < 1:
raise ValueError("early stopping rounds should be larger than 0 when it's integer")
if self.validation_freqs is None:
raise ValueError("validation freqs must be set when early stopping is enabled")
if not isinstance(self.use_first_metric_only, bool):
raise ValueError("use_first_metric_only should be a boolean")
return True
HeteroSecureBoostParam (HeteroBoostingParam)
¶
Define boosting tree parameters that used in federated ml.
Parameters:
| Name | Type | Description | Default |
|---|---|---|---|
task_type |
{'classification', 'regression'}, default: 'classification' |
task type |
'classification' |
tree_param |
DecisionTreeParam |
tree param |
<federatedml.param.boosting_param.DecisionTreeParam object at 0x7ff45d9b7950> |
objective_param |
ObjectiveParam Object, default: ObjectiveParam() |
objective param |
<federatedml.param.boosting_param.ObjectiveParam object at 0x7ff45d9b7ad0> |
learning_rate |
float, int or long |
the learning rate of secure boost. default: 0.3 |
0.3 |
num_trees |
int or float |
the max number of trees to build. default: 5 |
5 |
subsample_feature_rate |
float |
a float-number in [0, 1], default: 1.0 |
1.0 |
random_seed |
int |
seed that controls all random functions |
100 |
n_iter_no_change |
bool, |
when True and residual error less than tol, tree building process will stop. default: True |
True |
encrypt_param |
EncodeParam Object |
encrypt method use in secure boost, default: EncryptParam(), this parameter is only for hetero-secureboost |
<federatedml.param.encrypt_param.EncryptParam object at 0x7ff45d9b7b50> |
bin_num |
positive integer greater than 1 |
bin number use in quantile. default: 32 |
32 |
encrypted_mode_calculator_param |
EncryptedModeCalculatorParam object |
the calculation mode use in secureboost, default: EncryptedModeCalculatorParam(), only for hetero-secureboost |
<federatedml.param.encrypted_mode_calculation_param.EncryptedModeCalculatorParam object at 0x7ff45d9b7b90> |
use_missing |
bool |
use missing value in training process or not. default: False |
False |
zero_as_missing |
bool |
regard 0 as missing value or not, will be use only if use_missing=True, default: False |
False |
validation_freqs |
None or positive integer or container object in python |
Do validation in training process or Not. if equals None, will not do validation in train process; if equals positive integer, will validate data every validation_freqs epochs passes; if container object in python, will validate data if epochs belong to this container. e.g. validation_freqs = [10, 15], will validate data when epoch equals to 10 and 15. Default: None The default value is None, 1 is suggested. You can set it to a number larger than 1 in order to speed up training by skipping validation rounds. When it is larger than 1, a number which is divisible by "num_trees" is recommended, otherwise, you will miss the validation scores of last training iteration. |
None |
early_stopping_rounds |
integer larger than 0 |
will stop training if one metric of one validation data doesn’t improve in last early_stopping_round rounds, need to set validation freqs and will check early_stopping every at every validation epoch, |
None |
metrics |
list, default: [] |
Specify which metrics to be used when performing evaluation during training process. If set as empty, default metrics will be used. For regression tasks, default metrics are ['root_mean_squared_error', 'mean_absolute_error'], For binary-classificatiin tasks, default metrics are ['auc', 'ks']. For multi-classification tasks, default metrics are ['accuracy', 'precision', 'recall'] |
None |
use_first_metric_only |
bool |
use only the first metric for early stopping |
False |
complete_secure |
bool |
if use complete_secure, when use complete secure, build first tree using only guest features |
False |
sparse_optimization |
this parameter is abandoned in FATE-1.7.1 |
False |
|
run_goss |
bool |
activate Gradient-based One-Side Sampling, which selects large gradient and small gradient samples using top_rate and other_rate. |
False |
top_rate |
float |
the retain ratio of large gradient data, used when run_goss is True |
0.2 |
other_rate |
float |
the retain ratio of small gradient data, used when run_goss is True |
0.1 |
cipher_compress_error |
{None} |
This param is now abandoned |
None |
cipher_compress |
bool |
default is True, use cipher compressing to reduce computation cost and transfer cost |
True |
Source code in federatedml/param/boosting_param.py
class HeteroSecureBoostParam(HeteroBoostingParam):
"""
Define boosting tree parameters that used in federated ml.
Parameters
----------
task_type : {'classification', 'regression'}, default: 'classification'
task type
tree_param : DecisionTreeParam Object, default: DecisionTreeParam()
tree param
objective_param : ObjectiveParam Object, default: ObjectiveParam()
objective param
learning_rate : float, int or long
the learning rate of secure boost. default: 0.3
num_trees : int or float
the max number of trees to build. default: 5
subsample_feature_rate : float
a float-number in [0, 1], default: 1.0
random_seed: int
seed that controls all random functions
n_iter_no_change : bool,
when True and residual error less than tol, tree building process will stop. default: True
encrypt_param : EncodeParam Object
encrypt method use in secure boost, default: EncryptParam(), this parameter
is only for hetero-secureboost
bin_num: positive integer greater than 1
bin number use in quantile. default: 32
encrypted_mode_calculator_param: EncryptedModeCalculatorParam object
the calculation mode use in secureboost, default: EncryptedModeCalculatorParam(), only for hetero-secureboost
use_missing: bool
use missing value in training process or not. default: False
zero_as_missing: bool
regard 0 as missing value or not, will be use only if use_missing=True, default: False
validation_freqs: None or positive integer or container object in python
Do validation in training process or Not.
if equals None, will not do validation in train process;
if equals positive integer, will validate data every validation_freqs epochs passes;
if container object in python, will validate data if epochs belong to this container.
e.g. validation_freqs = [10, 15], will validate data when epoch equals to 10 and 15.
Default: None
The default value is None, 1 is suggested. You can set it to a number larger than 1 in order to
speed up training by skipping validation rounds. When it is larger than 1, a number which is
divisible by "num_trees" is recommended, otherwise, you will miss the validation scores
of last training iteration.
early_stopping_rounds: integer larger than 0
will stop training if one metric of one validation data
doesn’t improve in last early_stopping_round rounds,
need to set validation freqs and will check early_stopping every at every validation epoch,
metrics: list, default: []
Specify which metrics to be used when performing evaluation during training process.
If set as empty, default metrics will be used. For regression tasks, default metrics are
['root_mean_squared_error', 'mean_absolute_error'], For binary-classificatiin tasks, default metrics
are ['auc', 'ks']. For multi-classification tasks, default metrics are ['accuracy', 'precision', 'recall']
use_first_metric_only: bool
use only the first metric for early stopping
complete_secure: bool
if use complete_secure, when use complete secure, build first tree using only guest features
sparse_optimization:
this parameter is abandoned in FATE-1.7.1
run_goss: bool
activate Gradient-based One-Side Sampling, which selects large gradient and small
gradient samples using top_rate and other_rate.
top_rate: float
the retain ratio of large gradient data, used when run_goss is True
other_rate: float
the retain ratio of small gradient data, used when run_goss is True
cipher_compress_error: {None}
This param is now abandoned
cipher_compress: bool
default is True, use cipher compressing to reduce computation cost and transfer cost
"""
def __init__(self, tree_param: DecisionTreeParam = DecisionTreeParam(), task_type=consts.CLASSIFICATION,
objective_param=ObjectiveParam(),
learning_rate=0.3, num_trees=5, subsample_feature_rate=1.0, n_iter_no_change=True,
tol=0.0001, encrypt_param=EncryptParam(),
bin_num=32,
encrypted_mode_calculator_param=EncryptedModeCalculatorParam(),
predict_param=PredictParam(), cv_param=CrossValidationParam(),
validation_freqs=None, early_stopping_rounds=None, use_missing=False, zero_as_missing=False,
complete_secure=False, metrics=None, use_first_metric_only=False, random_seed=100,
binning_error=consts.DEFAULT_RELATIVE_ERROR,
sparse_optimization=False, run_goss=False, top_rate=0.2, other_rate=0.1,
cipher_compress_error=None, cipher_compress=True, new_ver=True,
callback_param=CallbackParam()):
super(HeteroSecureBoostParam, self).__init__(task_type, objective_param, learning_rate, num_trees,
subsample_feature_rate, n_iter_no_change, tol, encrypt_param,
bin_num, encrypted_mode_calculator_param, predict_param, cv_param,
validation_freqs, early_stopping_rounds, metrics=metrics,
use_first_metric_only=use_first_metric_only,
random_seed=random_seed,
binning_error=binning_error)
self.tree_param = copy.deepcopy(tree_param)
self.zero_as_missing = zero_as_missing
self.use_missing = use_missing
self.complete_secure = complete_secure
self.sparse_optimization = sparse_optimization
self.run_goss = run_goss
self.top_rate = top_rate
self.other_rate = other_rate
self.cipher_compress_error = cipher_compress_error
self.cipher_compress = cipher_compress
self.new_ver = new_ver
self.callback_param = copy.deepcopy(callback_param)
def check(self):
super(HeteroSecureBoostParam, self).check()
self.tree_param.check()
if type(self.use_missing) != bool:
raise ValueError('use missing should be bool type')
if type(self.zero_as_missing) != bool:
raise ValueError('zero as missing should be bool type')
self.check_boolean(self.complete_secure, 'complete_secure')
self.check_boolean(self.run_goss, 'run goss')
self.check_decimal_float(self.top_rate, 'top rate')
self.check_decimal_float(self.other_rate, 'other rate')
self.check_positive_number(self.other_rate, 'other_rate')
self.check_positive_number(self.top_rate, 'top_rate')
self.check_boolean(self.new_ver, 'code version switcher')
self.check_boolean(self.cipher_compress, 'cipher compress')
for p in ["early_stopping_rounds", "validation_freqs", "metrics",
"use_first_metric_only"]:
# if self._warn_to_deprecate_param(p, "", ""):
if self._deprecated_params_set.get(p):
if "callback_param" in self.get_user_feeded():
raise ValueError(f"{p} and callback param should not be set simultaneously,"
f"{self._deprecated_params_set}, {self.get_user_feeded()}")
else:
self.callback_param.callbacks = ["PerformanceEvaluate"]
break
descr = "boosting_param's"
if self._warn_to_deprecate_param("validation_freqs", descr, "callback_param's 'validation_freqs'"):
self.callback_param.validation_freqs = self.validation_freqs
if self._warn_to_deprecate_param("early_stopping_rounds", descr, "callback_param's 'early_stopping_rounds'"):
self.callback_param.early_stopping_rounds = self.early_stopping_rounds
if self._warn_to_deprecate_param("metrics", descr, "callback_param's 'metrics'"):
self.callback_param.metrics = self.metrics
if self._warn_to_deprecate_param("use_first_metric_only", descr, "callback_param's 'use_first_metric_only'"):
self.callback_param.use_first_metric_only = self.use_first_metric_only
if self.top_rate + self.other_rate >= 1:
raise ValueError('sum of top rate and other rate should be smaller than 1')
return True
__init__(self, tree_param=<federatedml.param.boosting_param.DecisionTreeParam object at 0x7ff45d9b7950>, task_type='classification', objective_param=<federatedml.param.boosting_param.ObjectiveParam object at 0x7ff45d9b7ad0>, learning_rate=0.3, num_trees=5, subsample_feature_rate=1.0, n_iter_no_change=True, tol=0.0001, encrypt_param=<federatedml.param.encrypt_param.EncryptParam object at 0x7ff45d9b7b50>, bin_num=32, encrypted_mode_calculator_param=<federatedml.param.encrypted_mode_calculation_param.EncryptedModeCalculatorParam object at 0x7ff45d9b7b90>, predict_param=<federatedml.param.predict_param.PredictParam object at 0x7ff45d9b7b10>, cv_param=<federatedml.param.cross_validation_param.CrossValidationParam object at 0x7ff45d9b79d0>, validation_freqs=None, early_stopping_rounds=None, use_missing=False, zero_as_missing=False, complete_secure=False, metrics=None, use_first_metric_only=False, random_seed=100, binning_error=0.0001, sparse_optimization=False, run_goss=False, top_rate=0.2, other_rate=0.1, cipher_compress_error=None, cipher_compress=True, new_ver=True, callback_param=<federatedml.param.callback_param.CallbackParam object at 0x7ff45d9b7c90>)
special
¶Source code in federatedml/param/boosting_param.py
def __init__(self, tree_param: DecisionTreeParam = DecisionTreeParam(), task_type=consts.CLASSIFICATION,
objective_param=ObjectiveParam(),
learning_rate=0.3, num_trees=5, subsample_feature_rate=1.0, n_iter_no_change=True,
tol=0.0001, encrypt_param=EncryptParam(),
bin_num=32,
encrypted_mode_calculator_param=EncryptedModeCalculatorParam(),
predict_param=PredictParam(), cv_param=CrossValidationParam(),
validation_freqs=None, early_stopping_rounds=None, use_missing=False, zero_as_missing=False,
complete_secure=False, metrics=None, use_first_metric_only=False, random_seed=100,
binning_error=consts.DEFAULT_RELATIVE_ERROR,
sparse_optimization=False, run_goss=False, top_rate=0.2, other_rate=0.1,
cipher_compress_error=None, cipher_compress=True, new_ver=True,
callback_param=CallbackParam()):
super(HeteroSecureBoostParam, self).__init__(task_type, objective_param, learning_rate, num_trees,
subsample_feature_rate, n_iter_no_change, tol, encrypt_param,
bin_num, encrypted_mode_calculator_param, predict_param, cv_param,
validation_freqs, early_stopping_rounds, metrics=metrics,
use_first_metric_only=use_first_metric_only,
random_seed=random_seed,
binning_error=binning_error)
self.tree_param = copy.deepcopy(tree_param)
self.zero_as_missing = zero_as_missing
self.use_missing = use_missing
self.complete_secure = complete_secure
self.sparse_optimization = sparse_optimization
self.run_goss = run_goss
self.top_rate = top_rate
self.other_rate = other_rate
self.cipher_compress_error = cipher_compress_error
self.cipher_compress = cipher_compress
self.new_ver = new_ver
self.callback_param = copy.deepcopy(callback_param)
check(self)
¶Source code in federatedml/param/boosting_param.py
def check(self):
super(HeteroSecureBoostParam, self).check()
self.tree_param.check()
if type(self.use_missing) != bool:
raise ValueError('use missing should be bool type')
if type(self.zero_as_missing) != bool:
raise ValueError('zero as missing should be bool type')
self.check_boolean(self.complete_secure, 'complete_secure')
self.check_boolean(self.run_goss, 'run goss')
self.check_decimal_float(self.top_rate, 'top rate')
self.check_decimal_float(self.other_rate, 'other rate')
self.check_positive_number(self.other_rate, 'other_rate')
self.check_positive_number(self.top_rate, 'top_rate')
self.check_boolean(self.new_ver, 'code version switcher')
self.check_boolean(self.cipher_compress, 'cipher compress')
for p in ["early_stopping_rounds", "validation_freqs", "metrics",
"use_first_metric_only"]:
# if self._warn_to_deprecate_param(p, "", ""):
if self._deprecated_params_set.get(p):
if "callback_param" in self.get_user_feeded():
raise ValueError(f"{p} and callback param should not be set simultaneously,"
f"{self._deprecated_params_set}, {self.get_user_feeded()}")
else:
self.callback_param.callbacks = ["PerformanceEvaluate"]
break
descr = "boosting_param's"
if self._warn_to_deprecate_param("validation_freqs", descr, "callback_param's 'validation_freqs'"):
self.callback_param.validation_freqs = self.validation_freqs
if self._warn_to_deprecate_param("early_stopping_rounds", descr, "callback_param's 'early_stopping_rounds'"):
self.callback_param.early_stopping_rounds = self.early_stopping_rounds
if self._warn_to_deprecate_param("metrics", descr, "callback_param's 'metrics'"):
self.callback_param.metrics = self.metrics
if self._warn_to_deprecate_param("use_first_metric_only", descr, "callback_param's 'use_first_metric_only'"):
self.callback_param.use_first_metric_only = self.use_first_metric_only
if self.top_rate + self.other_rate >= 1:
raise ValueError('sum of top rate and other rate should be smaller than 1')
return True
HeteroFastSecureBoostParam (HeteroSecureBoostParam)
¶
Source code in federatedml/param/boosting_param.py
class HeteroFastSecureBoostParam(HeteroSecureBoostParam):
def __init__(self, tree_param: DecisionTreeParam = DecisionTreeParam(), task_type=consts.CLASSIFICATION,
objective_param=ObjectiveParam(),
learning_rate=0.3, num_trees=5, subsample_feature_rate=1, n_iter_no_change=True,
tol=0.0001, encrypt_param=EncryptParam(),
bin_num=32,
encrypted_mode_calculator_param=EncryptedModeCalculatorParam(),
predict_param=PredictParam(), cv_param=CrossValidationParam(),
validation_freqs=None, early_stopping_rounds=None, use_missing=False, zero_as_missing=False,
complete_secure=False, tree_num_per_party=1, guest_depth=1, host_depth=1, work_mode='mix', metrics=None,
sparse_optimization=False, random_seed=100, binning_error=consts.DEFAULT_RELATIVE_ERROR,
cipher_compress_error=None, new_ver=True, run_goss=False, top_rate=0.2, other_rate=0.1,
cipher_compress=True, callback_param=CallbackParam()):
"""
Parameters
----------
work_mode: {"mix", "layered"}
mix: alternate using guest/host features to build trees. For example, the first 'tree_num_per_party' trees use guest features,
the second k trees use host features, and so on
layered: only support 2 party, when running layered mode, first 'host_depth' layer will use host features,
and then next 'guest_depth' will only use guest features
tree_num_per_party: int
every party will alternate build 'tree_num_per_party' trees until reach max tree num, this param is valid when work_mode is mix
guest_depth: int
guest will build last guest_depth of a decision tree using guest features, is valid when work mode is layered
host depth: int
host will build first host_depth of a decision tree using host features, is valid when work mode is layered
"""
super(HeteroFastSecureBoostParam, self).__init__(tree_param, task_type, objective_param, learning_rate,
num_trees, subsample_feature_rate, n_iter_no_change, tol,
encrypt_param, bin_num, encrypted_mode_calculator_param,
predict_param, cv_param, validation_freqs, early_stopping_rounds,
use_missing, zero_as_missing, complete_secure, metrics=metrics,
random_seed=random_seed,
sparse_optimization=sparse_optimization,
binning_error=binning_error,
cipher_compress_error=cipher_compress_error,
new_ver=new_ver,
cipher_compress=cipher_compress,
run_goss=run_goss, top_rate=top_rate, other_rate=other_rate,
)
self.tree_num_per_party = tree_num_per_party
self.guest_depth = guest_depth
self.host_depth = host_depth
self.work_mode = work_mode
self.callback_param = copy.deepcopy(callback_param)
def check(self):
super(HeteroFastSecureBoostParam, self).check()
if type(self.guest_depth).__name__ not in ["int", "long"] or self.guest_depth <= 0:
raise ValueError("guest_depth should be larger than 0")
if type(self.host_depth).__name__ not in ["int", "long"] or self.host_depth <= 0:
raise ValueError("host_depth should be larger than 0")
if type(self.tree_num_per_party).__name__ not in ["int", "long"] or self.tree_num_per_party <= 0:
raise ValueError("tree_num_per_party should be larger than 0")
work_modes = [consts.MIX_TREE, consts.LAYERED_TREE]
if self.work_mode not in work_modes:
raise ValueError('only work_modes: {} are supported, input work mode is {}'.
format(work_modes, self.work_mode))
return True
Methods¶
__init__(self, tree_param=<federatedml.param.boosting_param.DecisionTreeParam object at 0x7ff45d9b7c10>, task_type='classification', objective_param=<federatedml.param.boosting_param.ObjectiveParam object at 0x7ff45d9b7c50>, learning_rate=0.3, num_trees=5, subsample_feature_rate=1, n_iter_no_change=True, tol=0.0001, encrypt_param=<federatedml.param.encrypt_param.EncryptParam object at 0x7ff45d9b7d90>, bin_num=32, encrypted_mode_calculator_param=<federatedml.param.encrypted_mode_calculation_param.EncryptedModeCalculatorParam object at 0x7ff45d9b7dd0>, predict_param=<federatedml.param.predict_param.PredictParam object at 0x7ff45d9b7d50>, cv_param=<federatedml.param.cross_validation_param.CrossValidationParam object at 0x7ff45d9b7cd0>, validation_freqs=None, early_stopping_rounds=None, use_missing=False, zero_as_missing=False, complete_secure=False, tree_num_per_party=1, guest_depth=1, host_depth=1, work_mode='mix', metrics=None, sparse_optimization=False, random_seed=100, binning_error=0.0001, cipher_compress_error=None, new_ver=True, run_goss=False, top_rate=0.2, other_rate=0.1, cipher_compress=True, callback_param=<federatedml.param.callback_param.CallbackParam object at 0x7ff45d9b7ed0>)
special
¶Parameters:
| Name | Type | Description | Default |
|---|---|---|---|
work_mode |
{"mix", "layered"} |
'mix' |
|
tree_num_per_party |
int |
every party will alternate build 'tree_num_per_party' trees until reach max tree num, this param is valid when work_mode is mix |
1 |
guest_depth |
int |
guest will build last guest_depth of a decision tree using guest features, is valid when work mode is layered |
1 |
host depth |
int |
host will build first host_depth of a decision tree using host features, is valid when work mode is layered |
required |
Source code in federatedml/param/boosting_param.py
def __init__(self, tree_param: DecisionTreeParam = DecisionTreeParam(), task_type=consts.CLASSIFICATION,
objective_param=ObjectiveParam(),
learning_rate=0.3, num_trees=5, subsample_feature_rate=1, n_iter_no_change=True,
tol=0.0001, encrypt_param=EncryptParam(),
bin_num=32,
encrypted_mode_calculator_param=EncryptedModeCalculatorParam(),
predict_param=PredictParam(), cv_param=CrossValidationParam(),
validation_freqs=None, early_stopping_rounds=None, use_missing=False, zero_as_missing=False,
complete_secure=False, tree_num_per_party=1, guest_depth=1, host_depth=1, work_mode='mix', metrics=None,
sparse_optimization=False, random_seed=100, binning_error=consts.DEFAULT_RELATIVE_ERROR,
cipher_compress_error=None, new_ver=True, run_goss=False, top_rate=0.2, other_rate=0.1,
cipher_compress=True, callback_param=CallbackParam()):
"""
Parameters
----------
work_mode: {"mix", "layered"}
mix: alternate using guest/host features to build trees. For example, the first 'tree_num_per_party' trees use guest features,
the second k trees use host features, and so on
layered: only support 2 party, when running layered mode, first 'host_depth' layer will use host features,
and then next 'guest_depth' will only use guest features
tree_num_per_party: int
every party will alternate build 'tree_num_per_party' trees until reach max tree num, this param is valid when work_mode is mix
guest_depth: int
guest will build last guest_depth of a decision tree using guest features, is valid when work mode is layered
host depth: int
host will build first host_depth of a decision tree using host features, is valid when work mode is layered
"""
super(HeteroFastSecureBoostParam, self).__init__(tree_param, task_type, objective_param, learning_rate,
num_trees, subsample_feature_rate, n_iter_no_change, tol,
encrypt_param, bin_num, encrypted_mode_calculator_param,
predict_param, cv_param, validation_freqs, early_stopping_rounds,
use_missing, zero_as_missing, complete_secure, metrics=metrics,
random_seed=random_seed,
sparse_optimization=sparse_optimization,
binning_error=binning_error,
cipher_compress_error=cipher_compress_error,
new_ver=new_ver,
cipher_compress=cipher_compress,
run_goss=run_goss, top_rate=top_rate, other_rate=other_rate,
)
self.tree_num_per_party = tree_num_per_party
self.guest_depth = guest_depth
self.host_depth = host_depth
self.work_mode = work_mode
self.callback_param = copy.deepcopy(callback_param)
check(self)
¶Source code in federatedml/param/boosting_param.py
def check(self):
super(HeteroFastSecureBoostParam, self).check()
if type(self.guest_depth).__name__ not in ["int", "long"] or self.guest_depth <= 0:
raise ValueError("guest_depth should be larger than 0")
if type(self.host_depth).__name__ not in ["int", "long"] or self.host_depth <= 0:
raise ValueError("host_depth should be larger than 0")
if type(self.tree_num_per_party).__name__ not in ["int", "long"] or self.tree_num_per_party <= 0:
raise ValueError("tree_num_per_party should be larger than 0")
work_modes = [consts.MIX_TREE, consts.LAYERED_TREE]
if self.work_mode not in work_modes:
raise ValueError('only work_modes: {} are supported, input work mode is {}'.
format(work_modes, self.work_mode))
return True
HomoSecureBoostParam (BoostingParam)
¶
Parameters:
| Name | Type | Description | Default |
|---|---|---|---|
backend |
{'distributed', 'memory'} |
decides which backend to use when computing histograms for homo-sbt |
'distributed' |
Source code in federatedml/param/boosting_param.py
class HomoSecureBoostParam(BoostingParam):
"""
Parameters
----------
backend: {'distributed', 'memory'}
decides which backend to use when computing histograms for homo-sbt
"""
def __init__(self, tree_param: DecisionTreeParam = DecisionTreeParam(), task_type=consts.CLASSIFICATION,
objective_param=ObjectiveParam(),
learning_rate=0.3, num_trees=5, subsample_feature_rate=1, n_iter_no_change=True,
tol=0.0001, bin_num=32, predict_param=PredictParam(), cv_param=CrossValidationParam(),
validation_freqs=None, use_missing=False, zero_as_missing=False, random_seed=100,
binning_error=consts.DEFAULT_RELATIVE_ERROR, backend=consts.DISTRIBUTED_BACKEND,
callback_param=CallbackParam()):
super(HomoSecureBoostParam, self).__init__(task_type=task_type,
objective_param=objective_param,
learning_rate=learning_rate,
num_trees=num_trees,
subsample_feature_rate=subsample_feature_rate,
n_iter_no_change=n_iter_no_change,
tol=tol,
bin_num=bin_num,
predict_param=predict_param,
cv_param=cv_param,
validation_freqs=validation_freqs,
random_seed=random_seed,
binning_error=binning_error
)
self.use_missing = use_missing
self.zero_as_missing = zero_as_missing
self.tree_param = copy.deepcopy(tree_param)
self.backend = backend
self.callback_param = copy.deepcopy(callback_param)
def check(self):
super(HomoSecureBoostParam, self).check()
self.tree_param.check()
if type(self.use_missing) != bool:
raise ValueError('use missing should be bool type')
if type(self.zero_as_missing) != bool:
raise ValueError('zero as missing should be bool type')
if self.backend not in [consts.MEMORY_BACKEND, consts.DISTRIBUTED_BACKEND]:
raise ValueError('unsupported backend')
for p in ["validation_freqs", "metrics"]:
# if self._warn_to_deprecate_param(p, "", ""):
if self._deprecated_params_set.get(p):
if "callback_param" in self.get_user_feeded():
raise ValueError(f"{p} and callback param should not be set simultaneously,"
f"{self._deprecated_params_set}, {self.get_user_feeded()}")
else:
self.callback_param.callbacks = ["PerformanceEvaluate"]
break
descr = "boosting_param's"
if self._warn_to_deprecate_param("validation_freqs", descr, "callback_param's 'validation_freqs'"):
self.callback_param.validation_freqs = self.validation_freqs
if self._warn_to_deprecate_param("metrics", descr, "callback_param's 'metrics'"):
self.callback_param.metrics = self.metrics
return True
__init__(self, tree_param=<federatedml.param.boosting_param.DecisionTreeParam object at 0x7ff45d9b7a50>, task_type='classification', objective_param=<federatedml.param.boosting_param.ObjectiveParam object at 0x7ff45d9b7fd0>, learning_rate=0.3, num_trees=5, subsample_feature_rate=1, n_iter_no_change=True, tol=0.0001, bin_num=32, predict_param=<federatedml.param.predict_param.PredictParam object at 0x7ff45d9b7f50>, cv_param=<federatedml.param.cross_validation_param.CrossValidationParam object at 0x7ff45d9a30d0>, validation_freqs=None, use_missing=False, zero_as_missing=False, random_seed=100, binning_error=0.0001, backend='distributed', callback_param=<federatedml.param.callback_param.CallbackParam object at 0x7ff45d9a31d0>)
special
¶Source code in federatedml/param/boosting_param.py
def __init__(self, tree_param: DecisionTreeParam = DecisionTreeParam(), task_type=consts.CLASSIFICATION,
objective_param=ObjectiveParam(),
learning_rate=0.3, num_trees=5, subsample_feature_rate=1, n_iter_no_change=True,
tol=0.0001, bin_num=32, predict_param=PredictParam(), cv_param=CrossValidationParam(),
validation_freqs=None, use_missing=False, zero_as_missing=False, random_seed=100,
binning_error=consts.DEFAULT_RELATIVE_ERROR, backend=consts.DISTRIBUTED_BACKEND,
callback_param=CallbackParam()):
super(HomoSecureBoostParam, self).__init__(task_type=task_type,
objective_param=objective_param,
learning_rate=learning_rate,
num_trees=num_trees,
subsample_feature_rate=subsample_feature_rate,
n_iter_no_change=n_iter_no_change,
tol=tol,
bin_num=bin_num,
predict_param=predict_param,
cv_param=cv_param,
validation_freqs=validation_freqs,
random_seed=random_seed,
binning_error=binning_error
)
self.use_missing = use_missing
self.zero_as_missing = zero_as_missing
self.tree_param = copy.deepcopy(tree_param)
self.backend = backend
self.callback_param = copy.deepcopy(callback_param)
check(self)
¶Source code in federatedml/param/boosting_param.py
def check(self):
super(HomoSecureBoostParam, self).check()
self.tree_param.check()
if type(self.use_missing) != bool:
raise ValueError('use missing should be bool type')
if type(self.zero_as_missing) != bool:
raise ValueError('zero as missing should be bool type')
if self.backend not in [consts.MEMORY_BACKEND, consts.DISTRIBUTED_BACKEND]:
raise ValueError('unsupported backend')
for p in ["validation_freqs", "metrics"]:
# if self._warn_to_deprecate_param(p, "", ""):
if self._deprecated_params_set.get(p):
if "callback_param" in self.get_user_feeded():
raise ValueError(f"{p} and callback param should not be set simultaneously,"
f"{self._deprecated_params_set}, {self.get_user_feeded()}")
else:
self.callback_param.callbacks = ["PerformanceEvaluate"]
break
descr = "boosting_param's"
if self._warn_to_deprecate_param("validation_freqs", descr, "callback_param's 'validation_freqs'"):
self.callback_param.validation_freqs = self.validation_freqs
if self._warn_to_deprecate_param("metrics", descr, "callback_param's 'metrics'"):
self.callback_param.metrics = self.metrics
return True
Hetero Complete Secureboost¶
Now Hetero SecureBoost adds a new option: complete_secure. Once enabled, the boosting model will only use guest features to build the first decision tree. This can avoid label leakages, accord to SecureBoost: A Lossless Federated Learning Framework.
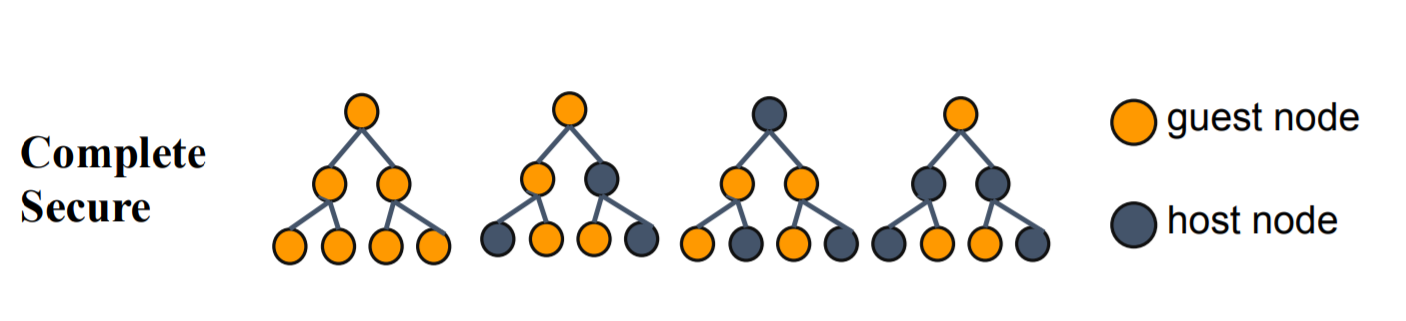
Examples¶
Example
## Hetero SecureBoost Configuration Usage Guide.
#### Example Tasks.
1. Binary-Class:
example-data: (1) guest: breast_hetero_guest.csv (2) host: breast_hetero_host.csv
dsl: test_secureboost_train_dsl.json
runtime_config: test_secureboost_train_binary_conf.json
2. Multi-Class:
example-data: (1) guest: vehicle_scale_hetero_guest.csv
(2) host: vehicle_scale_hetero_host.csv
dsl: test_secureboost_train_dsl.json
runtime_config: test_secureboost_train_multi_conf.json
3. Regression:
example-data: (1) guest: student_hetero_guest.csv
(2) host: student_hetero_host.csv
dsl: test_secureboost_train_dsl.json
runtime_config: test_secureboost_train_regression_conf.json
4. Multi-Host Regression
example-data: (1) guest: motor_hetero_guest.csv
(2) host1: motor_hetero_host_1.csv;
(3) host2: motor_hetero_host_2.csv
dsl: test_secureboost_train_dsl.json
runtime_config: test_secureboost_train_regression_multi_host_conf.json
5. Binary-Class With Missing Value
example-data: (1) guest: ionosphere_scale_hetero_guest.csv
(2) host: ionosphere_scale_hetero_host.csv
dsl: test_secureboost_train_dsl.json
runtime_config: test_secureboost_train_binary_with_missing_value_conf.json
This example also contains another two feature since FATE-1.1.
(1) evaluate data during training process, check the "validation_freqs" field in runtime_config
6. Early stopping example
example-data: (1) guest: student_hetero_guest.csv
(2) host: student_hetero_host.csv
dsl: test_secureboost_train_dsl.json
runtime_config: test_secureboost_train_with_early_stopping_conf.json
#### Cross Validation Class
1. Binary-Class:
example-data: (1) guest: breast_hetero_guest.csv
(2) host: breast_hetero_guest.csv
dsl: test_secureboost_cross_validation_dsl.json
runtime_config: test_secureboost_cross_validation_binary_conf.json
2. Multi-Class:
example-data: (1) guest: vehicle_scale_hetero_guest.csv
(2) host: vehicle_scal_a.csv
dsl: test_secureboost_cross_validation_binary_conf.json
runtime_config: test_secureboost_cross_validation_multi_conf.json
3. Regression:
example-data: (1) guest: student_hetero_guest.csv
(2) host: student_hetero_host.csv
dsl: test_secureboost_cross_validation_dsl.json
runtime_config: test_secureboost_cross_validation_regression_conf.json
Users can use following commands to run a task.
flow job submit -c ${runtime_config} -d ${dsl}
Moreover, after successfully running the training task, you can use it to predict too.
test_secureboost_warm_start_dsl.json
{
"components": {
"reader_0": {
"module": "Reader",
"output": {
"data": [
"data"
]
}
},
"data_transform_0": {
"module": "DataTransform",
"input": {
"data": {
"data": [
"reader_0.data"
]
}
},
"output": {
"data": [
"data"
],
"model": [
"model"
]
}
},
"intersection_0": {
"module": "Intersection",
"input": {
"data": {
"data": [
"data_transform_0.data"
]
}
},
"output": {
"data": [
"data"
],
"cache": [
"cache"
]
}
},
"hetero_secure_boost_0": {
"module": "HeteroSecureBoost",
"input": {
"data": {
"train_data": [
"intersection_0.data"
]
}
},
"output": {
"data": [
"data"
],
"model": [
"model"
]
}
},
"hetero_secure_boost_1": {
"module": "HeteroSecureBoost",
"input": {
"data": {
"train_data": [
"intersection_0.data"
]
},
"model": [
"hetero_secure_boost_0.model"
]
},
"output": {
"data": [
"data"
],
"model": [
"model"
]
}
},
"evaluation_0": {
"module": "Evaluation",
"input": {
"data": {
"data": [
"hetero_secure_boost_1.data"
]
}
},
"output": {
"data": [
"data"
]
}
}
}
}
test_secureboost_cross_validation_multi_conf.json
{
"dsl_version": 2,
"initiator": {
"role": "guest",
"party_id": 9999
},
"role": {
"host": [
9998
],
"guest": [
9999
]
},
"component_parameters": {
"common": {
"hetero_secure_boost_0": {
"task_type": "classification",
"objective_param": {
"objective": "cross_entropy"
},
"num_trees": 3,
"cv_param": {
"need_cv": true,
"n_splits": 5,
"shuffle": false,
"random_seed": 103
},
"validation_freqs": 1,
"encrypt_param": {
"method": "Paillier"
},
"tree_param": {
"max_depth": 3
}
}
},
"role": {
"host": {
"0": {
"reader_0": {
"table": {
"name": "vehicle_scale_hetero_host",
"namespace": "experiment"
}
},
"data_transform_0": {
"with_label": false
}
}
},
"guest": {
"0": {
"reader_0": {
"table": {
"name": "vehicle_scale_hetero_guest",
"namespace": "experiment"
}
},
"data_transform_0": {
"with_label": true,
"output_format": "dense"
}
}
}
}
}
}
test_secureboost_train_multi_conf.json
{
"dsl_version": 2,
"initiator": {
"role": "guest",
"party_id": 9999
},
"role": {
"host": [
9998
],
"guest": [
9999
]
},
"component_parameters": {
"common": {
"hetero_secure_boost_0": {
"task_type": "classification",
"objective_param": {
"objective": "cross_entropy"
},
"num_trees": 3,
"validation_freqs": 1,
"encrypt_param": {
"method": "Paillier"
},
"tree_param": {
"max_depth": 3
}
},
"evaluation_0": {
"eval_type": "multi"
}
},
"role": {
"host": {
"0": {
"reader_1": {
"table": {
"name": "vehicle_scale_hetero_host",
"namespace": "experiment"
}
},
"data_transform_0": {
"with_label": false
},
"data_transform_1": {
"with_label": false
},
"reader_0": {
"table": {
"name": "vehicle_scale_hetero_host",
"namespace": "experiment"
}
}
}
},
"guest": {
"0": {
"reader_1": {
"table": {
"name": "vehicle_scale_hetero_guest",
"namespace": "experiment"
}
},
"data_transform_0": {
"with_label": true,
"output_format": "dense"
},
"data_transform_1": {
"with_label": true,
"output_format": "dense"
},
"reader_0": {
"table": {
"name": "vehicle_scale_hetero_guest",
"namespace": "experiment"
}
}
}
}
}
}
}
test_secureboost_train_regression_multi_host_conf.json
{
"dsl_version": 2,
"initiator": {
"role": "guest",
"party_id": 9999
},
"role": {
"host": [
9998,
10000
],
"guest": [
9999
]
},
"component_parameters": {
"common": {
"hetero_secure_boost_0": {
"task_type": "regression",
"objective_param": {
"objective": "lse"
},
"num_trees": 3,
"validation_freqs": 1,
"encrypt_param": {
"method": "Paillier"
},
"tree_param": {
"max_depth": 3
}
},
"evaluation_0": {
"eval_type": "regression"
}
},
"role": {
"guest": {
"0": {
"data_transform_0": {
"with_label": true,
"label_name": "motor_speed",
"label_type": "float",
"output_format": "dense"
},
"data_transform_1": {
"with_label": true,
"label_name": "motor_speed",
"label_type": "float",
"output_format": "dense"
},
"reader_1": {
"table": {
"name": "motor_hetero_guest",
"namespace": "experiment"
}
},
"reader_0": {
"table": {
"name": "motor_hetero_guest",
"namespace": "experiment"
}
}
}
},
"host": {
"1": {
"data_transform_0": {
"with_label": false
},
"data_transform_1": {
"with_label": false
},
"reader_1": {
"table": {
"name": "motor_hetero_host_2",
"namespace": "experiment"
}
},
"reader_0": {
"table": {
"name": "motor_hetero_host_2",
"namespace": "experiment"
}
}
},
"0": {
"data_transform_0": {
"with_label": false
},
"data_transform_1": {
"with_label": false
},
"reader_1": {
"table": {
"name": "motor_hetero_host_1",
"namespace": "experiment"
}
},
"reader_0": {
"table": {
"name": "motor_hetero_host_1",
"namespace": "experiment"
}
}
}
}
}
}
}
test_secureboost_train_binary_without_cipher_compress_conf.json
{
"dsl_version": 2,
"initiator": {
"role": "guest",
"party_id": 9999
},
"role": {
"host": [
9998
],
"guest": [
9999
]
},
"component_parameters": {
"common": {
"hetero_secure_boost_0": {
"task_type": "classification",
"objective_param": {
"objective": "cross_entropy"
},
"num_trees": 3,
"validation_freqs": 1,
"encrypt_param": {
"method": "Paillier"
},
"tree_param": {
"max_depth": 3
},
"cipher_compress": false
},
"evaluation_0": {
"eval_type": "binary"
}
},
"role": {
"guest": {
"0": {
"reader_1": {
"table": {
"name": "breast_hetero_guest",
"namespace": "experiment"
}
},
"reader_0": {
"table": {
"name": "breast_hetero_guest",
"namespace": "experiment"
}
},
"data_transform_0": {
"with_label": true,
"output_format": "dense"
},
"data_transform_1": {
"with_label": true,
"output_format": "dense"
}
}
},
"host": {
"0": {
"reader_1": {
"table": {
"name": "breast_hetero_host",
"namespace": "experiment"
}
},
"reader_0": {
"table": {
"name": "breast_hetero_host",
"namespace": "experiment"
}
},
"data_transform_0": {
"with_label": false
},
"data_transform_1": {
"with_label": false
}
}
}
}
}
}
test_secureboost_train_binary_conf.json
{
"dsl_version": 2,
"initiator": {
"role": "guest",
"party_id": 9999
},
"role": {
"host": [
9998
],
"guest": [
9999
]
},
"component_parameters": {
"common": {
"hetero_secure_boost_0": {
"task_type": "classification",
"objective_param": {
"objective": "cross_entropy"
},
"num_trees": 3,
"validation_freqs": 1,
"encrypt_param": {
"method": "Paillier"
},
"tree_param": {
"max_depth": 3
}
},
"evaluation_0": {
"eval_type": "binary"
}
},
"role": {
"guest": {
"0": {
"reader_1": {
"table": {
"name": "breast_hetero_guest",
"namespace": "experiment"
}
},
"reader_0": {
"table": {
"name": "breast_hetero_guest",
"namespace": "experiment"
}
},
"data_transform_0": {
"with_label": true,
"output_format": "dense"
},
"data_transform_1": {
"with_label": true,
"output_format": "dense"
}
}
},
"host": {
"0": {
"reader_1": {
"table": {
"name": "breast_hetero_host",
"namespace": "experiment"
}
},
"reader_0": {
"table": {
"name": "breast_hetero_host",
"namespace": "experiment"
}
},
"data_transform_0": {
"with_label": false
},
"data_transform_1": {
"with_label": false
}
}
}
}
}
}
test_secureboost_train_binary_with_missing_value_conf.json
{
"dsl_version": 2,
"initiator": {
"role": "guest",
"party_id": 9999
},
"role": {
"host": [
9998
],
"guest": [
9999
]
},
"component_parameters": {
"common": {
"hetero_secure_boost_0": {
"task_type": "classification",
"objective_param": {
"objective": "cross_entropy"
},
"num_trees": 3,
"validation_freqs": 1,
"encrypt_param": {
"method": "Paillier"
},
"tree_param": {
"max_depth": 3
},
"use_missing": true
},
"evaluation_0": {
"eval_type": "binary"
}
},
"role": {
"guest": {
"0": {
"reader_1": {
"table": {
"name": "ionosphere_scale_hetero_guest",
"namespace": "experiment"
}
},
"data_transform_0": {
"with_label": true,
"label_name": "label",
"label_type": "int",
"output_format": "dense"
},
"data_transform_1": {
"with_label": true,
"label_name": "label",
"label_type": "int",
"output_format": "dense"
},
"reader_0": {
"table": {
"name": "ionosphere_scale_hetero_guest",
"namespace": "experiment"
}
}
}
},
"host": {
"0": {
"reader_1": {
"table": {
"name": "ionosphere_scale_hetero_host",
"namespace": "experiment"
}
},
"data_transform_0": {
"with_label": false
},
"data_transform_1": {
"with_label": false
},
"reader_0": {
"table": {
"name": "ionosphere_scale_hetero_host",
"namespace": "experiment"
}
}
}
}
}
}
}
test_secureboost_cross_validation_regression_conf.json
{
"dsl_version": 2,
"initiator": {
"role": "guest",
"party_id": 9999
},
"role": {
"host": [
9998
],
"guest": [
9999
]
},
"component_parameters": {
"common": {
"hetero_secure_boost_0": {
"task_type": "regression",
"objective_param": {
"objective": "lse"
},
"num_trees": 3,
"cv_param": {
"need_cv": true,
"n_splits": 5,
"shuffle": false,
"random_seed": 103
},
"validation_freqs": 1,
"encrypt_param": {
"method": "Paillier"
},
"tree_param": {
"max_depth": 3
}
}
},
"role": {
"host": {
"0": {
"reader_0": {
"table": {
"name": "student_hetero_host",
"namespace": "experiment"
}
},
"data_transform_0": {
"with_label": false
}
}
},
"guest": {
"0": {
"reader_0": {
"table": {
"name": "student_hetero_guest",
"namespace": "experiment"
}
},
"data_transform_0": {
"with_label": true,
"label_type": "float",
"output_format": "dense"
}
}
}
}
}
}
test_secureboost_train_binary_cipher_compress_conf.json
{
"dsl_version": 2,
"initiator": {
"role": "guest",
"party_id": 9999
},
"role": {
"host": [
9998
],
"guest": [
9999
]
},
"component_parameters": {
"common": {
"hetero_secure_boost_0": {
"task_type": "classification",
"objective_param": {
"objective": "cross_entropy"
},
"num_trees": 3,
"validation_freqs": 1,
"encrypt_param": {
"method": "Paillier"
},
"tree_param": {
"max_depth": 3
},
"cipher_compress_error": 8
},
"evaluation_0": {
"eval_type": "binary"
}
},
"role": {
"guest": {
"0": {
"reader_1": {
"table": {
"name": "breast_hetero_guest",
"namespace": "experiment"
}
},
"reader_0": {
"table": {
"name": "breast_hetero_guest",
"namespace": "experiment"
}
},
"data_transform_0": {
"with_label": true,
"output_format": "dense"
},
"data_transform_1": {
"with_label": true,
"output_format": "dense"
}
}
},
"host": {
"0": {
"reader_1": {
"table": {
"name": "breast_hetero_host",
"namespace": "experiment"
}
},
"reader_0": {
"table": {
"name": "breast_hetero_host",
"namespace": "experiment"
}
},
"data_transform_0": {
"with_label": false
},
"data_transform_1": {
"with_label": false
}
}
}
}
}
}
test_secureboost_cross_validation_dsl.json
{
"components": {
"reader_0": {
"module": "Reader",
"output": {
"data": [
"data"
]
}
},
"data_transform_0": {
"module": "DataTransform",
"input": {
"data": {
"data": [
"reader_0.data"
]
}
},
"output": {
"data": [
"data"
],
"model": [
"model"
]
}
},
"intersection_0": {
"module": "Intersection",
"input": {
"data": {
"data": [
"data_transform_0.data"
]
}
},
"output": {
"data": [
"data"
]
}
},
"hetero_secure_boost_0": {
"module": "HeteroSecureBoost",
"input": {
"data": {
"train_data": [
"intersection_0.data"
]
}
},
"output": {
"data": [
"data"
],
"model": [
"model"
]
}
}
}
}
test_secureboost_train_complete_secure_conf.json
{
"dsl_version": 2,
"initiator": {
"role": "guest",
"party_id": 9999
},
"role": {
"host": [
9998
],
"guest": [
9999
]
},
"component_parameters": {
"common": {
"hetero_secure_boost_0": {
"task_type": "classification",
"objective_param": {
"objective": "cross_entropy"
},
"num_trees": 3,
"validation_freqs": 1,
"encrypt_param": {
"method": "Paillier"
},
"tree_param": {
"max_depth": 3
},
"complete_secure": true
},
"evaluation_0": {
"eval_type": "binary"
}
},
"role": {
"guest": {
"0": {
"data_transform_0": {
"with_label": true,
"output_format": "dense"
},
"data_transform_1": {
"with_label": true,
"output_format": "dense"
},
"reader_0": {
"table": {
"name": "breast_hetero_guest",
"namespace": "experiment"
}
},
"reader_1": {
"table": {
"name": "breast_hetero_guest",
"namespace": "experiment"
}
}
}
},
"host": {
"0": {
"data_transform_0": {
"with_label": false
},
"data_transform_1": {
"with_label": false
},
"reader_0": {
"table": {
"name": "breast_hetero_host",
"namespace": "experiment"
}
},
"reader_1": {
"table": {
"name": "breast_hetero_host",
"namespace": "experiment"
}
}
}
}
}
}
}
test_secureboost_cross_validation_binary_conf.json
{
"dsl_version": 2,
"initiator": {
"role": "guest",
"party_id": 9999
},
"role": {
"host": [
9998
],
"guest": [
9999
]
},
"component_parameters": {
"common": {
"hetero_secure_boost_0": {
"task_type": "classification",
"objective_param": {
"objective": "cross_entropy"
},
"num_trees": 3,
"cv_param": {
"need_cv": true,
"n_splits": 5,
"shuffle": false,
"random_seed": 103
},
"validation_freqs": 1,
"encrypt_param": {
"method": "Paillier"
},
"tree_param": {
"max_depth": 3
}
}
},
"role": {
"guest": {
"0": {
"reader_0": {
"table": {
"name": "breast_hetero_guest",
"namespace": "experiment"
}
},
"data_transform_0": {
"with_label": true,
"output_format": "dense"
}
}
},
"host": {
"0": {
"reader_0": {
"table": {
"name": "breast_hetero_host",
"namespace": "experiment"
}
},
"data_transform_0": {
"with_label": false
}
}
}
}
}
}
test_predict_dsl.json
{
"components": {
"reader_0": {
"module": "Reader",
"output": {
"data": [
"data"
]
}
},
"intersection_0": {
"input": {
"data": {
"data": [
"data_transform_0.data"
]
}
},
"module": "Intersection",
"output": {
"data": [
"data"
]
}
},
"data_transform_0": {
"input": {
"data": {
"data": [
"reader_0.data"
]
},
"model": [
"pipeline.data_transform_0.model"
]
},
"module": "DataTransform",
"output": {
"data": [
"data"
]
}
},
"hetero_secure_boost_0": {
"input": {
"data": {
"test_data": [
"intersection_0.data"
]
},
"model": [
"pipeline.hetero_secure_boost_0.model"
]
},
"module": "HeteroSecureBoost",
"output": {
"data": [
"data"
]
}
}
}
}
test_secureboost_warm_start_conf.json
{
"dsl_version": 2,
"initiator": {
"role": "guest",
"party_id": 9999
},
"role": {
"arbiter": [
9999
],
"host": [
10000
],
"guest": [
9999
]
},
"component_parameters": {
"role": {
"host": {
"0": {
"data_transform_0": {
"with_label": false
},
"reader_0": {
"table": {
"name": "breast_hetero_host",
"namespace": "experiment"
}
}
}
},
"guest": {
"0": {
"data_transform_0": {
"with_label": true
},
"reader_0": {
"table": {
"name": "breast_hetero_guest",
"namespace": "experiment"
}
}
}
}
},
"common": {
"data_transform_0": {
"output_format": "dense"
},
"hetero_secure_boost_0": {
"task_type": "classification",
"objective_param": {
"objective": "cross_entropy"
},
"num_trees": 3,
"encrypt_param": {
"method": "Paillier"
},
"tree_param": {
"max_depth": 3
}
},
"hetero_secure_boost_1": {
"task_type": "classification",
"objective_param": {
"objective": "cross_entropy"
},
"num_trees": 3,
"encrypt_param": {
"method": "Paillier"
},
"tree_param": {
"max_depth": 3
},
"callback_param": {
"callbacks": [
"PerformanceEvaluate"
],
"validation_freqs": 1
}
},
"evaluation_0": {
"eval_type": "binary"
}
}
}
}
test_secureboost_train_with_early_stopping_conf.json
{
"dsl_version": 2,
"initiator": {
"role": "guest",
"party_id": 9999
},
"role": {
"host": [
9998
],
"guest": [
9999
]
},
"component_parameters": {
"common": {
"hetero_secure_boost_0": {
"task_type": "regression",
"objective_param": {
"objective": "lse"
},
"num_trees": 3,
"validation_freqs": 1,
"encrypt_param": {
"method": "Paillier"
},
"early_stopping_rounds": 1,
"tree_param": {
"max_depth": 3
}
},
"evaluation_0": {
"eval_type": "regression"
}
},
"role": {
"guest": {
"0": {
"data_transform_1": {
"with_label": true,
"output_format": "dense"
},
"data_transform_0": {
"with_label": true,
"output_format": "dense"
},
"reader_0": {
"table": {
"name": "student_hetero_guest",
"namespace": "experiment"
}
},
"reader_1": {
"table": {
"name": "student_hetero_guest",
"namespace": "experiment"
}
}
}
},
"host": {
"0": {
"data_transform_1": {
"with_label": false
},
"data_transform_0": {
"with_label": false
},
"reader_0": {
"table": {
"name": "student_hetero_host",
"namespace": "experiment"
}
},
"reader_1": {
"table": {
"name": "student_hetero_host",
"namespace": "experiment"
}
}
}
}
}
}
}
test_predict_conf.json
{
"dsl_version": 2,
"initiator": {
"role": "guest",
"party_id": 9999
},
"role": {
"host": [
10000
],
"guest": [
9999
]
},
"job_parameters": {
"common": {
"model_id": "guest-10000#host-9999#model",
"model_version": "20200928174750711017114",
"job_type": "predict"
}
},
"component_parameters": {
"role": {
"guest": {
"0": {
"reader_0": {
"table": {
"name": "breast_hetero_guest",
"namespace": "experiment"
}
}
}
},
"host": {
"0": {
"reader_0": {
"table": {
"name": "breast_hetero_host",
"namespace": "experiment"
}
}
}
}
}
}
}
test_secureboost_train_regression_conf.json
{
"dsl_version": 2,
"initiator": {
"role": "guest",
"party_id": 9999
},
"role": {
"host": [
9998
],
"guest": [
9999
]
},
"component_parameters": {
"common": {
"hetero_secure_boost_0": {
"task_type": "regression",
"objective_param": {
"objective": "lse"
},
"num_trees": 3,
"validation_freqs": 1,
"encrypt_param": {
"method": "Paillier"
},
"tree_param": {
"max_depth": 3
}
},
"evaluation_0": {
"eval_type": "regression"
}
},
"role": {
"host": {
"0": {
"data_transform_0": {
"with_label": false
},
"reader_1": {
"table": {
"name": "student_hetero_host",
"namespace": "experiment"
}
},
"data_transform_1": {
"with_label": false
},
"reader_0": {
"table": {
"name": "student_hetero_host",
"namespace": "experiment"
}
}
}
},
"guest": {
"0": {
"data_transform_0": {
"with_label": true,
"label_type": "float",
"output_format": "dense"
},
"reader_1": {
"table": {
"name": "student_hetero_guest",
"namespace": "experiment"
}
},
"data_transform_1": {
"with_label": true,
"label_type": "float",
"output_format": "dense"
},
"reader_0": {
"table": {
"name": "student_hetero_guest",
"namespace": "experiment"
}
}
}
}
}
}
}
hetero_secureboost_testsuite.json
{
"data": [
{
"file": "examples/data/breast_hetero_guest.csv",
"head": 1,
"partition": 4,
"table_name": "breast_hetero_guest",
"namespace": "experiment",
"role": "guest_0"
},
{
"file": "examples/data/breast_hetero_host.csv",
"head": 1,
"partition": 4,
"table_name": "breast_hetero_host",
"namespace": "experiment",
"role": "host_0"
},
{
"file": "examples/data/vehicle_scale_hetero_guest.csv",
"head": 1,
"partition": 4,
"table_name": "vehicle_scale_hetero_guest",
"namespace": "experiment",
"role": "guest_0"
},
{
"file": "examples/data/vehicle_scale_hetero_host.csv",
"head": 1,
"partition": 4,
"table_name": "vehicle_scale_hetero_host",
"namespace": "experiment",
"role": "host_0"
},
{
"file": "examples/data/student_hetero_guest.csv",
"head": 1,
"partition": 4,
"table_name": "student_hetero_guest",
"namespace": "experiment",
"role": "guest_0"
},
{
"file": "examples/data/student_hetero_host.csv",
"head": 1,
"partition": 4,
"table_name": "student_hetero_host",
"namespace": "experiment",
"role": "host_0"
},
{
"file": "examples/data/ionosphere_scale_hetero_guest.csv",
"head": 1,
"partition": 4,
"table_name": "ionosphere_scale_hetero_guest",
"namespace": "experiment",
"role": "guest_0"
},
{
"file": "examples/data/ionosphere_scale_hetero_host.csv",
"head": 1,
"partition": 4,
"table_name": "ionosphere_scale_hetero_host",
"namespace": "experiment",
"role": "host_0"
},
{
"file": "examples/data/motor_hetero_guest.csv",
"head": 1,
"partition": 4,
"table_name": "motor_hetero_guest",
"namespace": "experiment",
"role": "guest_0"
},
{
"file": "examples/data/motor_hetero_host_1.csv",
"head": 1,
"partition": 4,
"table_name": "motor_hetero_host_1",
"namespace": "experiment",
"role": "host_0"
},
{
"file": "examples/data/motor_hetero_host_2.csv",
"head": 1,
"partition": 4,
"table_name": "motor_hetero_host_2",
"namespace": "experiment",
"role": "host_1"
}
],
"tasks": {
"train_binary": {
"conf": "./test_secureboost_train_binary_conf.json",
"dsl": "./test_secureboost_train_dsl.json"
},
"warm_start_train": {
"conf": "./test_secureboost_warm_start_conf.json",
"dsl": "./test_secureboost_warm_start_dsl.json"
},
"train_complete_secure": {
"conf": "./test_secureboost_train_complete_secure_conf.json",
"dsl": "./test_secureboost_train_dsl.json"
},
"train_binary_without_cipher_compress": {
"conf": "./test_secureboost_train_binary_without_cipher_compress_conf.json",
"dsl": "./test_secureboost_train_dsl.json"
},
"train_binary_predict": {
"conf": "./test_predict_conf.json",
"dsl": "./test_predict_dsl.json",
"deps": "train_binary"
},
"train_multi": {
"conf": "./test_secureboost_train_multi_conf.json",
"dsl": "./test_secureboost_train_dsl.json"
},
"train_regression": {
"conf": "./test_secureboost_train_regression_conf.json",
"dsl": "./test_secureboost_train_dsl.json"
},
"cv_binary": {
"conf": "./test_secureboost_cross_validation_binary_conf.json",
"dsl": "./test_secureboost_cross_validation_dsl.json"
},
"cv_multi": {
"conf": "./test_secureboost_cross_validation_multi_conf.json",
"dsl": "./test_secureboost_cross_validation_dsl.json"
},
"cv_regression": {
"conf": "./test_secureboost_cross_validation_regression_conf.json",
"dsl": "./test_secureboost_cross_validation_dsl.json"
},
"train_binary_with_missing_value": {
"conf": "./test_secureboost_train_binary_with_missing_value_conf.json",
"dsl": "./test_secureboost_train_dsl.json"
},
"train_multi_host": {
"conf": "./test_secureboost_train_regression_multi_host_conf.json",
"dsl": "./test_secureboost_train_dsl.json"
},
"train_with_early_stopping": {
"conf": "./test_secureboost_train_with_early_stopping_conf.json",
"dsl": "./test_secureboost_train_dsl.json"
}
}
}
test_secureboost_train_dsl.json
{
"components": {
"reader_0": {
"module": "Reader",
"output": {
"data": [
"data"
]
}
},
"reader_1": {
"module": "Reader",
"output": {
"data": [
"data"
]
}
},
"data_transform_0": {
"module": "DataTransform",
"input": {
"data": {
"data": [
"reader_0.data"
]
}
},
"output": {
"data": [
"data"
],
"model": [
"model"
]
}
},
"data_transform_1": {
"module": "DataTransform",
"input": {
"data": {
"data": [
"reader_1.data"
]
},
"model": [
"data_transform_0.model"
]
},
"output": {
"data": [
"data"
],
"model": [
"model"
]
}
},
"intersection_0": {
"module": "Intersection",
"input": {
"data": {
"data": [
"data_transform_0.data"
]
}
},
"output": {
"data": [
"data"
]
}
},
"intersection_1": {
"module": "Intersection",
"input": {
"data": {
"data": [
"data_transform_1.data"
]
}
},
"output": {
"data": [
"data"
]
}
},
"hetero_secure_boost_0": {
"module": "HeteroSecureBoost",
"input": {
"data": {
"train_data": [
"intersection_0.data"
],
"validate_data": [
"intersection_1.data"
]
}
},
"output": {
"data": [
"data"
],
"model": [
"model"
]
}
},
"evaluation_0": {
"module": "Evaluation",
"input": {
"data": {
"data": [
"hetero_secure_boost_0.data"
]
}
},
"output": {
"data": [
"data"
]
}
}
}
}
Hetero Fast SecureBoost¶
We support Hetero Fast SecureBoost, in abbreviation, fast SBT, in FATE-1.5. The fast SBT uses guest features and host features alternately to build trees, in order to save encryption costs and communication costs. In fast SBT, we support MIX mode and LAYERED mode and they use different strategies while building decision trees.
MIX mode¶
In mix mode, we offer a new parameter 'tree_num_per_party'. Every participated party will build 'tree_num_per_party' trees using their local features, and this procedure will be repeated until reach the max tree number. Figure 5 illustrates the mix mode.
While building a guest tree, the guest party side simply computes g/h and finds the best split points, other host parties will skip this tree and wait. While building a host tree, the related host party will receive encrypted g/h and find the best split points with the assistant of the guest party. The structures of host trees and split points will be preserved on the host side while leaf weights will be preserved on the guest side. In this way, encryption and communication costs are reduced by half. (If there are two parties)
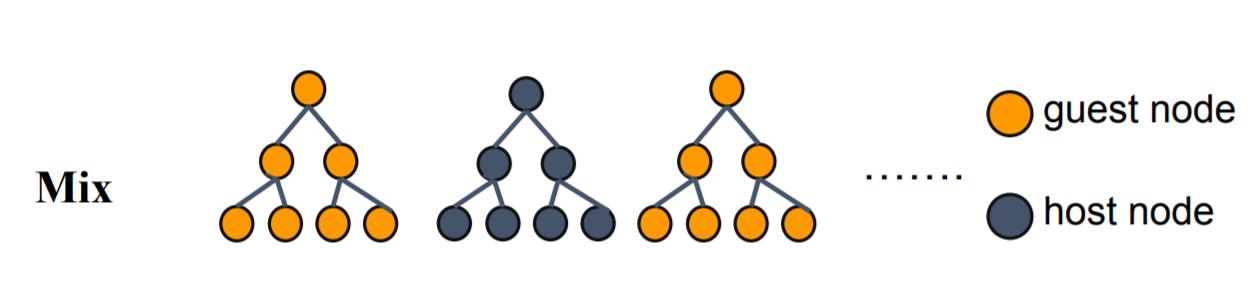
While conducting inference, every party will traverse its trees locally. All hosts will send the final leaf id to guests and the guest retrieves leaf weights using received leaf id. The prediction only needs one communication in mix mode.
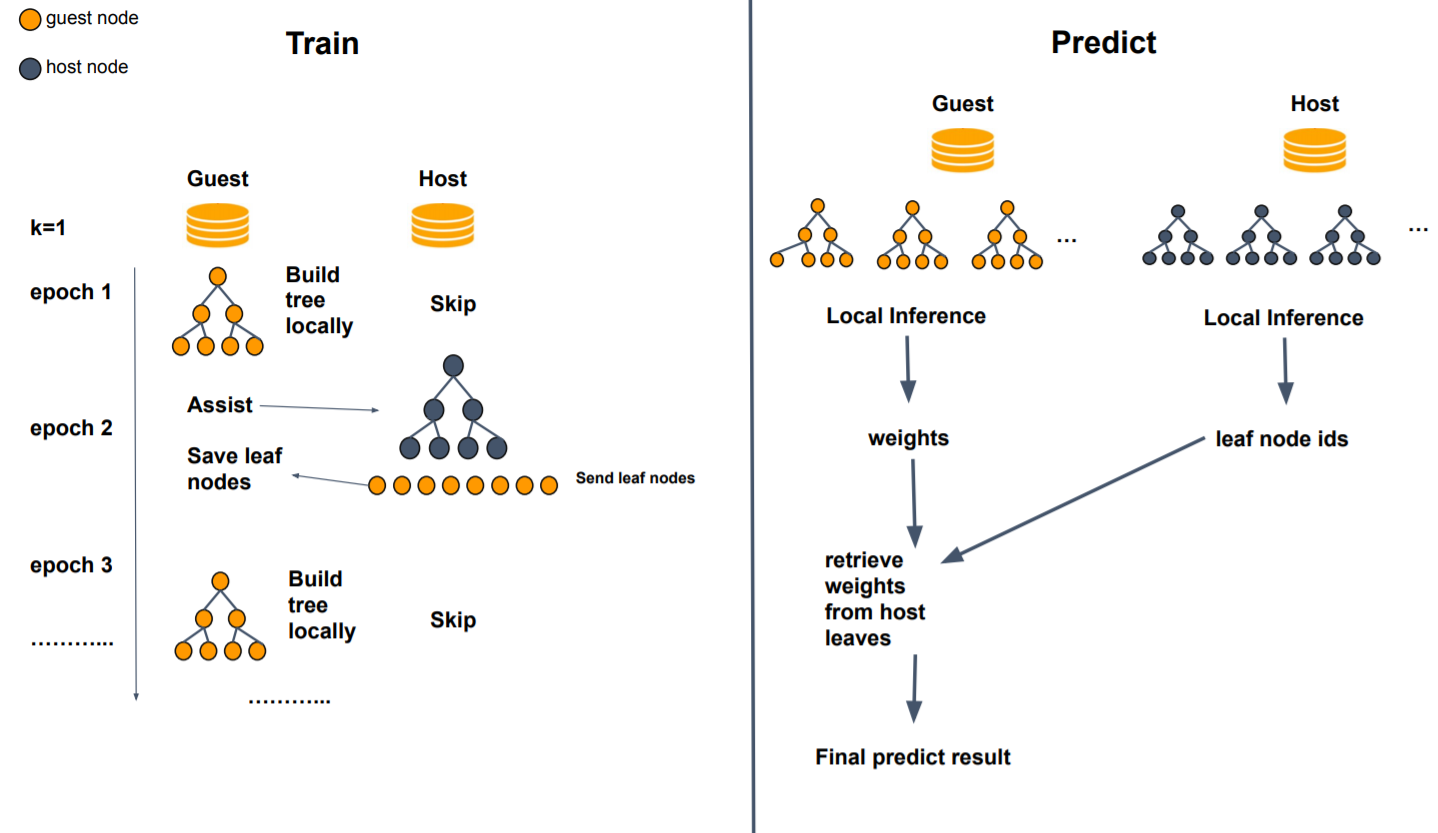
LAYERED mode¶
In layered mode, only supports one guest party and one host party. The host will be responsible for building the first "host_depth" layers, with the help of the guest, and the guest will be responsible for the next "guest_depth" layers. All trees will be built in this 'layered' manner.
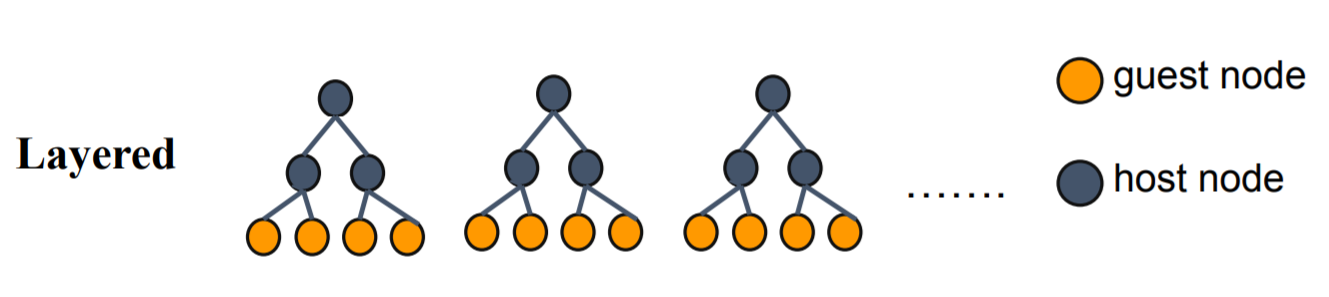
The benefits of layered mod is obvious, like the mix mode, parts of communication costs and encryption costs will be saved in the process of training. When predicting, we only need one communication because all host can conduct inferences of host layers locally.
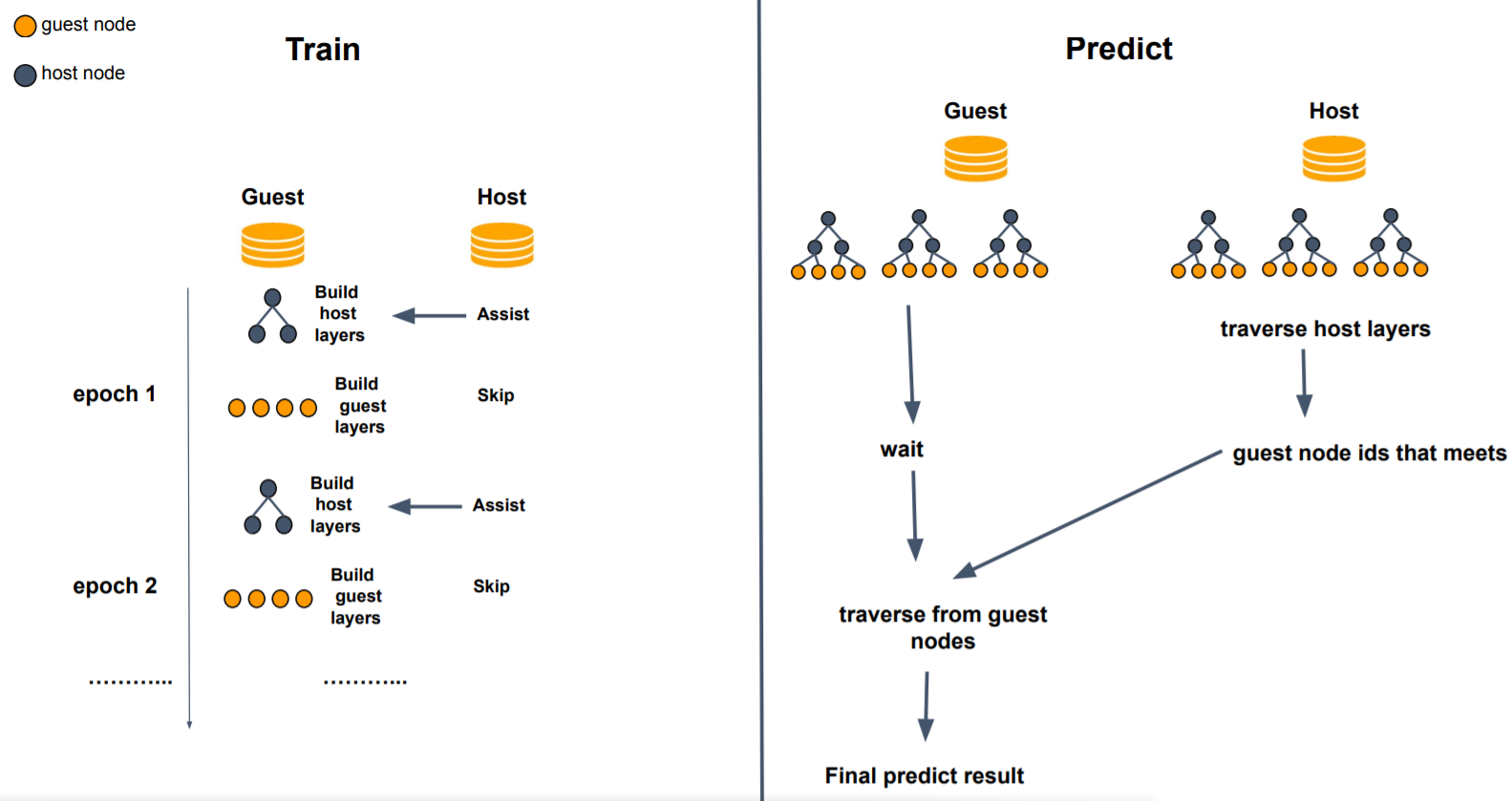
According to experiments on our standard data sets, mix mode and layered mode of Fast SBT can still give performances (sometimes even better) equivalent to standard Hetero SecureBoost, even the training data is unbalanced distributed in different parties or contains noise features. (Binary, multi-class, and regression tasks are tested). At the same time, the time consumption of FAST SBT is reduced by 30% ~ 50% on average.
Optimization in learning¶
Fast SBT uses guest features and host features alternately by trees/layers to reduce encryption and communication costs.
- Prediction only needs one communication round.
Applications¶
Fast SBT supports the following applications.
- binary classification, the objective function is sigmoid cross-entropy
- multi classification, the objective function is softmax cross-entropy
- regression, objective function includes least-squared-error-loss、least-absolutely-error-loss、huber-loss、tweedie-loss、fair-loss、 log-cosh-loss
Other features¶
- In mix mode, every host parties only keep their own tree models. Guest will only keep guest trees and host leaves.
- In mix mode, host side support feature importance calculation (split type is supported, gain type is not supported)
- In layered mode, model exporting setting is the same as the normal-SBT.
- The time consumption of FAST SBT is reduced by 30% ~ 50% on average.