Federated Linear Regression¶
Linear Regression(LinR) is a simple statistic model widely used for predicting continuous numbers. FATE provides Heterogeneous Linear Regression(HeteroLinR). HeteroLinR also supports multi-Host training. You can specify multiple hosts in the job configuration file like the provided examples/dsl/v2/hetero_linear_regression.
Here we simplify participants of the federation process into three parties. Party A represents Guest, party B represents Host. Party C, which is also known as “Arbiter,” is a third party that works as coordinator. Party C is responsible for generating private and public keys.
Heterogeneous LinR¶
The process of HeteroLinR training is shown below:
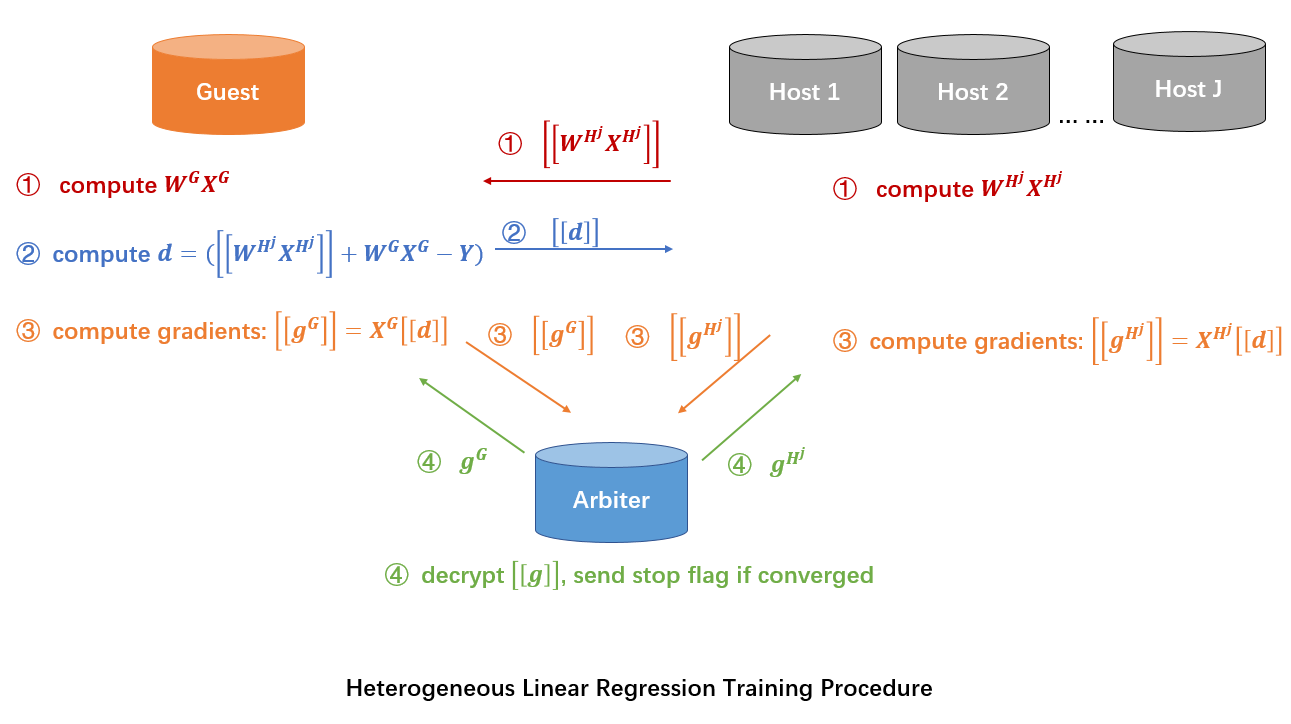
Figure 1 (Federated HeteroLinR Principle)¶
A sample alignment process is conducted before training. The sample alignment process identifies overlapping samples in databases of all parties. The federated model is built based on the overlapping samples. The whole sample alignment process is conducted in encryption mode, and so confidential information (e.g. sample ids) will not be leaked.
In the training process, party A and party B each compute the elements needed for final gradients. Arbiter aggregates, calculates, and transfers back the final gradients to corresponding parties. For more details on the secure model-building process, please refer to this paper.
Param¶
-
class
LinearParam(penalty='L2', tol=0.0001, alpha=1.0, optimizer='sgd', batch_size=-1, learning_rate=0.01, init_param=<federatedml.param.init_model_param.InitParam object>, max_iter=20, early_stop='diff', predict_param=<federatedml.param.predict_param.PredictParam object>, encrypt_param=<federatedml.param.encrypt_param.EncryptParam object>, sqn_param=<federatedml.param.sqn_param.StochasticQuasiNewtonParam object>, encrypted_mode_calculator_param=<federatedml.param.encrypted_mode_calculation_param.EncryptedModeCalculatorParam object>, cv_param=<federatedml.param.cross_validation_param.CrossValidationParam object>, decay=1, decay_sqrt=True, validation_freqs=None, early_stopping_rounds=None, stepwise_param=<federatedml.param.stepwise_param.StepwiseParam object>, metrics=None, use_first_metric_only=False, floating_point_precision=23)¶ Parameters used for Linear Regression.
- Parameters
penalty (str, 'L1' or 'L2'. default: 'L2') – Penalty method used in LinR. Please note that, when using encrypted version in HeteroLinR, ‘L1’ is not supported.
tol (float, default: 1e-4) – The tolerance of convergence
alpha (float, default: 1.0) – Regularization strength coefficient.
optimizer (str, 'sgd', 'rmsprop', 'adam', 'sqn', or 'adagrad', default: 'sgd') – Optimize method
batch_size (int, default: -1) – Batch size when updating model. -1 means use all data in a batch. i.e. Not to use mini-batch strategy.
learning_rate (float, default: 0.01) – Learning rate
max_iter (int, default: 20) – The maximum iteration for training.
init_param (InitParam object, default: default InitParam object) – Init param method object.
early_stop (str, 'diff' or 'abs' or 'weight_dff', default: 'diff') –
- Method used to judge convergence.
diff: Use difference of loss between two iterations to judge whether converge.
abs: Use the absolute value of loss to judge whether converge. i.e. if loss < tol, it is converged.
weight_diff: Use difference between weights of two consecutive iterations
predict_param (PredictParam object, default: default PredictParam object) –
encrypt_param (EncryptParam object, default: default EncryptParam object) –
encrypted_mode_calculator_param (EncryptedModeCalculatorParam object, default: default EncryptedModeCalculatorParam object) –
cv_param (CrossValidationParam object, default: default CrossValidationParam object) –
decay (int or float, default: 1) – Decay rate for learning rate. learning rate will follow the following decay schedule. lr = lr0/(1+decay*t) if decay_sqrt is False. If decay_sqrt is True, lr = lr0 / sqrt(1+decay*t) where t is the iter number.
decay_sqrt (Bool, default: True) – lr = lr0/(1+decay*t) if decay_sqrt is False, otherwise, lr = lr0 / sqrt(1+decay*t)
validation_freqs (int, list, tuple, set, or None) – validation frequency during training, required when using early stopping. The default value is None, 1 is suggested. You can set it to a number larger than 1 in order to speed up training by skipping validation rounds. When it is larger than 1, a number which is divisible by “max_iter” is recommended, otherwise, you will miss the validation scores of the last training iteration.
early_stopping_rounds (int, default: None) – If positive number specified, at every specified training rounds, program checks for early stopping criteria. Validation_freqs must also be set when using early stopping.
metrics (list or None, default: None) – Specify which metrics to be used when performing evaluation during training process. If metrics have not improved at early_stopping rounds, trianing stops before convergence. If set as empty, default metrics will be used. For regression tasks, default metrics are [‘root_mean_squared_error’, ‘mean_absolute_error’]
use_first_metric_only (bool, default: False) – Indicate whether to use the first metric in metrics as the only criterion for early stopping judgement.
floating_point_precision (None or integer, if not None, use floating_point_precision-bit to speed up calculation,) –
- e.g.: convert an x to round(x * 2**floating_point_precision) during Paillier operation, divide
the result by 2**floating_point_precision in the end.
Features¶
L1 & L2 regularization
Mini-batch mechanism
Five optimization methods:
- sgd
gradient descent with arbitrary batch size
- rmsprop
RMSProp
- adam
Adam
- adagrad
AdaGrad
- nesterov_momentum_sgd
Nesterov Momentum
- stochastic quansi-newton
The algorithm details can refer to this paper.
Three converge criteria:
- diff
Use difference of loss between two iterations, not available for multi-host training
- abs
Use the absolute value of loss
- weight_diff
Use difference of model weights
Support multi-host modeling task. For details on how to configure for multi-host modeling task, please refer to this guide
Support validation for every arbitrary iterations
Learning rate decay mechanism
Support early stopping mechanism, which checks for performance change on specified metrics over training rounds. Early stopping is triggered when no improvement is found at early stopping rounds.
Support sparse format data as input.
Support stepwise. For details on stepwise mode, please refer stepwise .