Hetero Feature Binning¶
Feature binning or data binning is a data pre-processing technique. It can be use to reduce the effects of minor observation errors, calculate information values and so on.
Currently, we provide quantile binning and bucket binning methods. To achieve quantile binning approach, we have used a special data structure mentioned in this [paper]. Feel free to check out the detail algorithm in the paper.
As for calculating the federated iv and woe values, the following figure can describe the principle properly.

Figure 1 (Federated Feature Binning Principle)¶
As the figure shows, B party which has the data labels encrypt its labels with Addiction homomorphic encryption and then send to A. A static each bin’s label sum and send back. Then B can calculate woe and iv base on the given information.
For multiple hosts, it is similar with one host case. Guest sends its encrypted label information to all hosts, and each of the hosts calculates and sends back the static info.
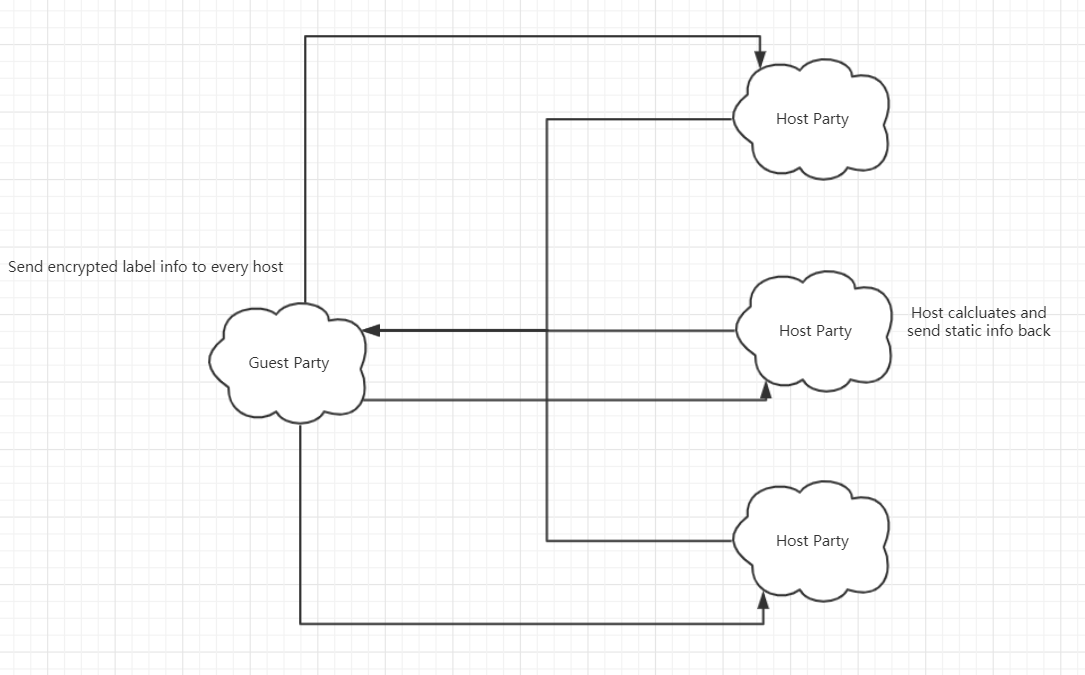
Figure 2: Multi-Host Binning Principle¶
For optimal binning, each party use quantile binning or bucket binning find initial split points. Then Guest will send encrypted labels to Host. Host use them calculate histogram of each bin and send back to Guest. Then start optimal binning methods.

Figure 3: Multi-Host Binning Principle¶
There exist two kinds of methods, merge-optimal binning and split-optimal binning. When choosing metrics as iv, gini or chi-square, merge type optimal binning will be used. On the other hand, if ks is choosed, split type optimal binning will be used.
Param¶
-
class
FeatureBinningParam(method='quantile', compress_thres=10000, head_size=10000, error=0.0001, bin_num=10, bin_indexes=-1, bin_names=None, adjustment_factor=0.5, transform_param=<federatedml.param.feature_binning_param.TransformParam object>, local_only=False, category_indexes=None, category_names=None, need_run=True, skip_static=False)¶ Define the feature binning method
- Parameters
method (str, 'quantile', 'bucket' or 'optimal', default: 'quantile') – Binning method.
compress_thres (int, default: 10000) – When the number of saved summaries exceed this threshold, it will call its compress function
head_size (int, default: 10000) – The buffer size to store inserted observations. When head list reach this buffer size, the QuantileSummaries object start to generate summary(or stats) and insert into its sampled list.
error (float, 0 <= error < 1 default: 0.001) – The error of tolerance of binning. The final split point comes from original data, and the rank of this value is close to the exact rank. More precisely, floor((p - 2 * error) * N) <= rank(x) <= ceil((p + 2 * error) * N) where p is the quantile in float, and N is total number of data.
bin_num (int, bin_num > 0, default: 10) – The max bin number for binning
bin_indexes (list of int or int, default: -1) – Specify which columns need to be binned. -1 represent for all columns. If you need to indicate specific cols, provide a list of header index instead of -1.
bin_names (list of string, default: []) – Specify which columns need to calculated. Each element in the list represent for a column name in header.
adjustment_factor (float, default: 0.5) – the adjustment factor when calculating WOE. This is useful when there is no event or non-event in a bin. Please note that this parameter will NOT take effect for setting in host.
category_indexes (list of int or int, default: []) –
Specify which columns are category features. -1 represent for all columns. List of int indicate a set of such features. For category features, bin_obj will take its original values as split_points and treat them as have been binned. If this is not what you expect, please do NOT put it into this parameters.
The number of categories should not exceed bin_num set above.
category_names (list of string, default: []) – Use column names to specify category features. Each element in the list represent for a column name in header.
local_only (bool, default: False) – Whether just provide binning method to guest party. If true, host party will do nothing. Warnings: This parameter will be deprecated in future version.
transform_param (TransformParam) – Define how to transfer the binned data.
need_run (bool, default True) – Indicate if this module needed to be run
skip_static (bool, default False) – If true, binning will not calculate iv, woe etc. In this case, optimal-binning will not be supported.
-
class
HeteroFeatureBinningParam(method='quantile', compress_thres=10000, head_size=10000, error=0.0001, bin_num=10, bin_indexes=-1, bin_names=None, adjustment_factor=0.5, transform_param=<federatedml.param.feature_binning_param.TransformParam object>, optimal_binning_param=<federatedml.param.feature_binning_param.OptimalBinningParam object>, local_only=False, category_indexes=None, category_names=None, encrypt_param=<federatedml.param.encrypt_param.EncryptParam object>, need_run=True, skip_static=False)¶
-
class
HomoFeatureBinningParam(method='virtual_summary', compress_thres=10000, head_size=10000, error=0.0001, sample_bins=100, bin_num=10, bin_indexes=-1, bin_names=None, adjustment_factor=0.5, transform_param=<federatedml.param.feature_binning_param.TransformParam object>, category_indexes=None, category_names=None, need_run=True, skip_static=False, max_iter=100)¶
-
class
OptimalBinningParam(metric_method='iv', min_bin_pct=0.05, max_bin_pct=1.0, init_bin_nums=1000, mixture=True, init_bucket_method='quantile')¶ Indicate optimal binning params
- Parameters
metric_method (str, default: "iv") – The algorithm metric method. Support iv, gini, ks, chi-square
- min_bin_pct: float, default: 0.05
The minimum percentage of each bucket
- max_bin_pct: float, default: 1.0
The maximum percentage of each bucket
- init_bin_nums: int, default 100
Number of bins when initialize
- mixture: bool, default: True
Whether each bucket need event and non-event records
- init_bucket_method: str default: quantile
Init bucket methods. Accept quantile and bucket.
-
class
TransformParam(transform_cols=- 1, transform_names=None, transform_type='bin_num')¶ Define how to transfer the cols
- Parameters
transform_cols (list of column index, default: -1) – Specify which columns need to be transform. If column index is None, None of columns will be transformed. If it is -1, it will use same columns as cols in binning module.
transform_names (list of string, default: []) – Specify which columns need to calculated. Each element in the list represent for a column name in header.
- transform_type: str, ‘bin_num’or ‘woe’ or None default: ‘bin_num’
- Specify which value these columns going to replace.
bin_num: Transfer original feature value to bin index in which this value belongs to.
woe: This is valid for guest party only. It will replace original value to its woe value
None: nothing will be replaced.
Features¶
Support Quantile Binning based on quantile summary algorithm.
Support Bucket Binning.
Support missing value input by ignoring them.
Support sparse data format generated by dataio component.
Support calculating woe and iv as well as counting positive and negative cases for each bin.
Support transforming data into bin indexes.
Support multiple hosts binning.
Support 4 types of optimal binning.
Support asymmetric binning methods on Host & Guest sides.
Hetero Feature Selection¶
Feature selection is a process that selects a subset of features for model construction. Take good advantage of feature selection can improve model performance.
In this version, we provide several filter methods for feature selection.
Param¶
-
class
CommonFilterParam(metrics, filter_type='threshold', take_high=True, threshold=1, host_thresholds=None, select_federated=True)¶ All of the following parameters can set with a single value or a list of those values. When setting one single value, it means using only one metric to filter while a list represent for using multiple metrics.
Please note that if some of the following values has been set as list, all of them should have same length. Otherwise, error will be raised. And if there exist a list type parameter, the metrics should be in list type.
- Parameters
metrics (str or list, default: depends on the specific filter) – Indicate what metrics are used in this filter
filter_type (str, default: threshold) – Should be one of “threshold”, “top_k” or “top_percentile”
take_high (bool, default: True) – When filtering, taking highest values or not.
threshold (float or int, default: 1) – If filter type is threshold, this is the threshold value. If it is “top_k”, this is the k value. If it is top_percentile, this is the percentile threshold.
host_thresholds (List of float or List of List of float or None, default: None) – Set threshold for different host. If None, use same threshold as guest. If provided, the order should map with the host id setting.
select_federated (bool, default: True) – Whether select federated with other parties or based on local variables
-
class
CorrelationFilterParam(sort_metric='iv', threshold=0.1, select_federated=True)¶ - This filter follow this specific rules:
Sort all the columns from high to low based on specific metric, eg. iv.
- Traverse each sorted column. If there exists other columns with whom the
absolute values of correlation are larger than threshold, they will be filtered.
- Parameters
sort_metric (str, default: iv) – Specify which metric to be used to sort features.
threshold (float or int, default: 0.1) – Correlation threshold
select_federated (bool, default: True) – Whether select federated with other parties or based on local variables
-
class
FeatureSelectionParam(select_col_indexes=-1, select_names=None, filter_methods=None, unique_param=<federatedml.param.feature_selection_param.UniqueValueParam object>, iv_value_param=<federatedml.param.feature_selection_param.IVValueSelectionParam object>, iv_percentile_param=<federatedml.param.feature_selection_param.IVPercentileSelectionParam object>, iv_top_k_param=<federatedml.param.feature_selection_param.IVTopKParam object>, variance_coe_param=<federatedml.param.feature_selection_param.VarianceOfCoeSelectionParam object>, outlier_param=<federatedml.param.feature_selection_param.OutlierColsSelectionParam object>, manually_param=<federatedml.param.feature_selection_param.ManuallyFilterParam object>, percentage_value_param=<federatedml.param.feature_selection_param.PercentageValueParam object>, iv_param=<federatedml.param.feature_selection_param.CommonFilterParam object>, statistic_param=<federatedml.param.feature_selection_param.CommonFilterParam object>, psi_param=<federatedml.param.feature_selection_param.CommonFilterParam object>, vif_param=<federatedml.param.feature_selection_param.CommonFilterParam object>, sbt_param=<federatedml.param.feature_selection_param.CommonFilterParam object>, correlation_param=<federatedml.param.feature_selection_param.CorrelationFilterParam object>, need_run=True)¶ Define the feature selection parameters.
- Parameters
select_col_indexes (list or int, default: -1) – Specify which columns need to calculated. -1 represent for all columns.
select_names (list of string, default: []) – Specify which columns need to calculated. Each element in the list represent for a column name in header.
filter_methods (list, ["manually", "iv_filter", "statistic_filter",) –
- “psi_filter”, “hetero_sbt_filter”, “homo_sbt_filter”,
”hetero_fast_sbt_filter”, “percentage_value”, “vif_filter”, “correlation_filter”],
default: [“manually”]
The following methods will be deprecated in future version: “unique_value”, “iv_value_thres”, “iv_percentile”, “coefficient_of_variation_value_thres”, “outlier_cols”
Specify the filter methods used in feature selection. The orders of filter used is depended on this list. Please be notified that, if a percentile method is used after some certain filter method, the percentile represent for the ratio of rest features.
e.g. If you have 10 features at the beginning. After first filter method, you have 8 rest. Then, you want top 80% highest iv feature. Here, we will choose floor(0.8 * 8) = 6 features instead of 8.
unique_param (filter the columns if all values in this feature is the same) –
iv_value_param (Use information value to filter columns. If this method is set, a float threshold need to be provided.) – Filter those columns whose iv is smaller than threshold. Will be deprecated in the future.
iv_percentile_param (Use information value to filter columns. If this method is set, a float ratio threshold) – need to be provided. Pick floor(ratio * feature_num) features with higher iv. If multiple features around the threshold are same, all those columns will be keep. Will be deprecated in the future.
variance_coe_param (Use coefficient of variation to judge whether filtered or not.) – Will be deprecated in the future.
outlier_param (Filter columns whose certain percentile value is larger than a threshold.) – Will be deprecated in the future.
percentage_value_param (Filter the columns that have a value that exceeds a certain percentage.) –
iv_param (Setting how to filter base on iv. It support take high mode only. All of "threshold",) – “top_k” and “top_percentile” are accepted. Check more details in CommonFilterParam. To use this filter, hetero-feature-binning module has to be provided.
statistic_param (Setting how to filter base on statistic values. All of "threshold",) – “top_k” and “top_percentile” are accepted. Check more details in CommonFilterParam. To use this filter, data_statistic module has to be provided.
psi_param (Setting how to filter base on psi values. All of "threshold",) – “top_k” and “top_percentile” are accepted. Its take_high properties should be False to choose lower psi features. Check more details in CommonFilterParam. To use this filter, data_statistic module has to be provided.
need_run (bool, default True) – Indicate if this module needed to be run
-
class
IVPercentileSelectionParam(percentile_threshold=1.0, local_only=False)¶ Use information values to select features.
- Parameters
percentile_threshold (float, 0 <= percentile_threshold <= 1.0, default: 1.0) – Percentile threshold for iv_percentile method
-
class
IVTopKParam(k=10, local_only=False)¶ Use information values to select features.
- Parameters
k (int, should be greater than 0, default: 10) – Percentile threshold for iv_percentile method
-
class
IVValueSelectionParam(value_threshold=0.0, host_thresholds=None, local_only=False)¶ Use information values to select features.
- Parameters
value_threshold (float, default: 1.0) – Used if iv_value_thres method is used in feature selection.
host_thresholds (List of float or None, default: None) – Set threshold for different host. If None, use same threshold as guest. If provided, the order should map with the host id setting.
-
class
ManuallyFilterParam(filter_out_indexes=None, filter_out_names=None, left_col_indexes=None, left_col_names=None)¶ Specified columns that need to be filtered. If exist, it will be filtered directly, otherwise, ignore it.
- Parameters
filter_out_indexes (list of int, default: None) – Specify columns’ indexes to be filtered out
filter_out_names (list of string, default: None) – Specify columns’ names to be filtered out
left_col_indexes (list of int, default: None) – Specify left_col_index
left_col_names (list of string, default: None) – Specify left col names
Filter_out or left parameters only works for this specific filter. For instances (Both) –
you set some columns left (if) –
this filter but those columns are filtered by other filters (in) –
columns will NOT left in final. (those) –
note that (left_col_indexes & left_col_names) cannot use with (Please) – (filter_out_indexes & filter_out_names) simultaneously.
-
class
OutlierColsSelectionParam(percentile=1.0, upper_threshold=1.0)¶ Given percentile and threshold. Judge if this quantile point is larger than threshold. Filter those larger ones.
- Parameters
percentile (float, [0., 1.] default: 1.0) – The percentile points to compare.
upper_threshold (float, default: 1.0) – Percentile threshold for coefficient_of_variation_percentile method
-
class
PercentageValueParam(upper_pct=1.0)¶ Filter the columns that have a value that exceeds a certain percentage.
- Parameters
upper_pct (float, [0.1, 1.], default: 1.0) – The upper percentage threshold for filtering, upper_pct should not be less than 0.1.
-
class
UniqueValueParam(eps=1e-05)¶ Use the difference between max-value and min-value to judge.
- Parameters
eps (float, default: 1e-5) – The column(s) will be filtered if its difference is smaller than eps.
-
class
VarianceOfCoeSelectionParam(value_threshold=1.0)¶ Use coefficient of variation to select features. When judging, the absolute value will be used.
- Parameters
value_threshold (float, default: 1.0) – Used if coefficient_of_variation_value_thres method is used in feature selection. Filter those columns who has smaller coefficient of variance than the threshold.
Features¶
unique_value: filter the columns if all values in this feature is the same
- iv_filter: Use iv as criterion to selection features. Support three mode: threshold value, top-k and top-percentile.
threshold value: Filter those columns whose iv is smaller than threshold. You can also set different threshold for each party.
top-k: Sort features from larger iv to smaller and take top k features in the sorted result.
top-percentile. Sort features from larger to smaller and take top percentile.
statistic_filter: Use statistic values calculate from DataStatistic component. Support coefficient of variance, missing value, percentile value etc. You can pick the columns with higher statistic values or smaller values as you need.
psi_filter: Take PSI component as input isometric model. Then, use its psi value as criterion of selection.
hetero_sbt_filter/homo_sbt_filter/hetero_fast_sbt_filter: Take secureboost component as input isometric model. And use feature importance as criterion of selection.
manually: Indicate features that need to be filtered.
percentage_value: Filter the columns that have a value that exceeds a certain percentage.
Besides, we support multi-host federated feature selection for iv filters. Hosts encode feature names and send the feature ids that are involved in feature selection. Guest use iv filters’ logic to judge whether a feature is left or not. Then guest sends result back to hosts. Hosts decode feature ids back to feature names and obtain selection results.
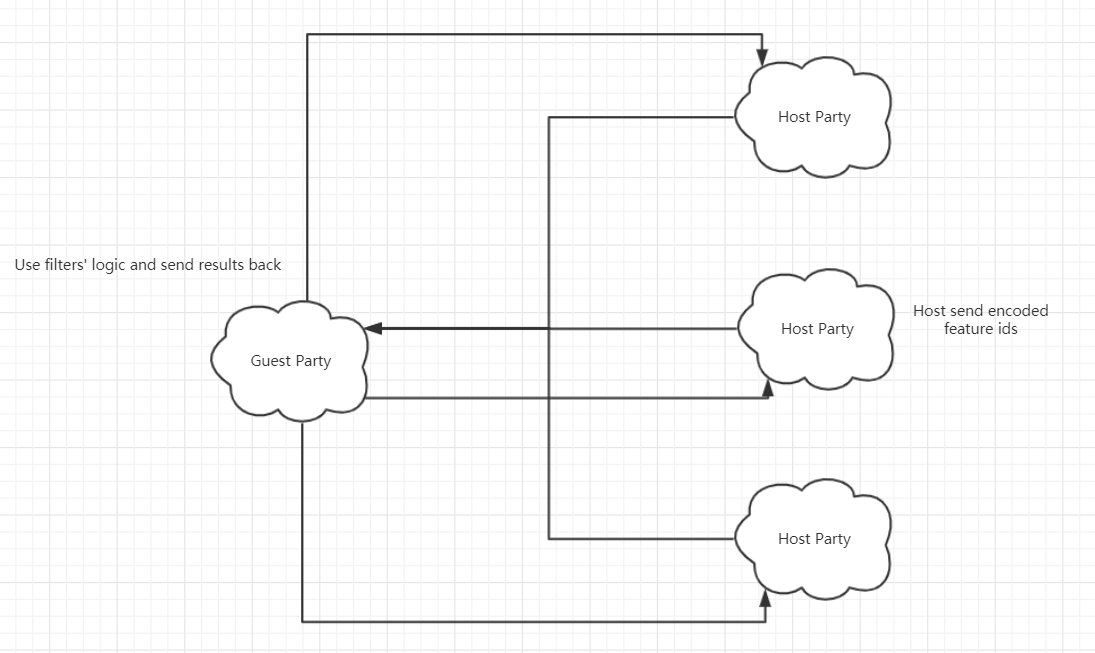
Figure 3: Multi-Host Selection Principle</div>¶
More feature selection methods will be provided. Please make suggestions by submitting an issue.
Federated Sampling¶
From Fate v0.2 supports sample method. Sample module supports two sample modes: random sample mode and stratified sample mode.
In random mode, “downsample” and “upsample” methods are provided. Users can set the sample parameter “fractions”, which is the sample ratio within data.
In stratified mode, “downsample” and “upsample” methods are also provided. Users can set the sample parameter “fractions” too, but it should be a list of tuples in the form (label_i, ratio).
Tuples in the list each specify the sample ratio of corresponding label. e.g.
[(0, 1.5), (1, 2.5), (3, 3.5)]
Param¶
-
class
SampleParam(mode='random', method='downsample', fractions=None, random_state=None, task_type='hetero', need_run=True)¶ Define the sample method
- Parameters
mode (str, accepted 'random','stratified'' only in this version, specify sample to use, default: 'random') –
method (str, accepted 'downsample','upsample' only in this version. default: 'downsample') –
fractions (None or float or list, if mode equals to random, it should be a float number greater than 0,) – otherwise a list of elements of pairs like [label_i, sample_rate_i], e.g. [[0, 0.5], [1, 0.8], [2, 0.3]]. default: None
random_state (int, RandomState instance or None, default: None) –
need_run (bool, default True) – Indicate if this module needed to be run
Feature Scale¶
Feature scale is a process that scales each feature along column. Feature Scale module supports min-max scale and standard scale.
min-max scale: this estimator scales and translates each feature individually such that it is in the given range on the training set, e.g. between min and max value of each feature.
standard scale: standardize features by removing the mean and scaling to unit variance
Param¶
-
class
ScaleParam(method='standard_scale', mode='normal', scale_col_indexes=- 1, scale_names=None, feat_upper=None, feat_lower=None, with_mean=True, with_std=True, need_run=True)¶ Define the feature scale parameters.
- Parameters
method (str, like scale in sklearn, now it support "min_max_scale" and "standard_scale", and will support other scale method soon.) – Default standard_scale, which will do nothing for scale
mode (str, the mode support "normal" and "cap". for mode is "normal", the feat_upper and feat_lower is the normal value like "10" or "3.1" and for "cap", feat_upper and) – feature_lower will between 0 and 1, which means the percentile of the column. Default “normal”
feat_upper (int or float or list of int or float, the upper limit in the column.) – If use list, mode must be “normal”, and list length should equal to the number of features to scale. If the scaled value is larger than feat_upper, it will be set to feat_upper. Default None.
feat_lower (int or float or list of int or float, the lower limit in the column.) – If use list, mode must be “normal”, and list length should equal to the number of features to scale. If the scaled value is less than feat_lower, it will be set to feat_lower. Default None.
scale_col_indexes (list,the idx of column in scale_column_idx will be scaled, while the idx of column is not in, it will not be scaled.) –
scale_names (list of string, default: []Specify which columns need to scaled. Each element in the list represent for a column name in header.) –
with_mean (bool, used for "standard_scale". Default True.) –
with_std (bool, used for "standard_scale". Default True.) – The standard scale of column x is calculated as : z = (x - u) / s, where u is the mean of the column and s is the standard deviation of the column. if with_mean is False, u will be 0, and if with_std is False, s will be 1.
need_run (bool, default True) – Indicate if this module needed to be run
OneHot Encoder¶
OneHot encoding is a process by which category variables are converted to binary values. The detailed info could be found in [OneHot wiki]
Param¶
-
class
OneHotEncoderParam(transform_col_indexes=- 1, transform_col_names=None, need_run=True)¶ - Parameters
transform_col_indexes (list or int, default: -1) – Specify which columns need to calculated. -1 represent for all columns.
transform_col_names (list of string, default: []) – Specify which columns need to calculated. Each element in the list represent for a column name in header.
- need_run: bool, default True
Indicate if this module needed to be run
Homo OneHot Encoder¶
OneHot Encoding is a process by which category variables are converted to binary values. The detailed info could be found in [OneHot wiki]
Param¶
-
class
HomoOneHotParam(transform_col_indexes=- 1, transform_col_names=None, need_run=True, need_alignment=True)¶ - Parameters
transform_col_indexes (list or int, default: -1) – Specify which columns need to calculated. -1 represent for all columns.
need_run (bool, default True) – Indicate if this module needed to be run
need_alignment (bool, default True) – Indicated whether alignment of features is turned on
Column Expand¶
Column Expand is used for adding arbitrary number of columns with user-provided values. This module is run directly on table object(raw data), before data entering DataIO.
Param¶
-
class
ColumnExpandParam(append_header=None, method='manual', fill_value=1e-08, need_run=True)¶ Define method used for expanding column
- Parameters
append_header (None, str, List[str] default: None) – Name(s) for appended feature(s). If None is given, module outputs the original input value without any operation.
method (str, default: 'manual') – If method is ‘manual’, use user-specified fill_value to fill in new features.
fill_value (int, float, str, List[int], List[float], List[str] default: 1e-8) – Used for filling expanded feature columns. If given a list, length of the list must match that of append_header
need_run (bool, default: True) – Indicate if this module needed to be run.